逻辑求值器
数学 处理 说明式 知识, 计算机 科学处理 命令式 知识:
- 程序语言要求用 算法的方式 描述解决问题过程
- 实际上程序语言也常提供一些 说明性描述 方式:
- 用户可以省去计算过程的很多细节描述,例如输出函数的格式描述
多数程序语言要求用定义数学函数的方式组织程序: 程序描述的是“怎么做” 所描述的计算有明确方向,从输入到输出 描述函数关系的表达式,也给出了计算出结果的方法 定义的过程完成从参数到结果的计算
同样也有些例外。比如:
- 约束传递 系统中的计算对象是约束关系,没有明确的计算方向和顺序,其基础系统要做很多工作来支持计算
- 非确定性 程序求值器里的表达式可有多个值,求值器设法根据表达式描述的关系找出满足要求的
逻辑式程序
逻辑程序设计 可看作上面想法的一种推广,它基于 关系模型 和称为 合一 的重要操作,其编程就是用 逻辑公式描述事物之间的约束关系 (属于“是什么”的范畴),支持 多重结果和无确定方向 的计算
逻辑程序设计特别适合一些应用领域的需要
如数据库查询语言 Datalog ,支持查询基于已有事实的隐含事实
一个“是什么”的描述可能蕴涵许多“怎样做”的过程,比如:
(define (append x y) (if (null? x) y (cons (car x) (append (cdr x) y))))
可以认为,这个程序表达的是两条规则:
- 对任何一个表 y,空表与其拼接得到的表就是 y 本身
- 对任何表 u, v, y, z: (cons u v) 与 y 拼接得到 (cons u z) 的条件是 v 与 y 的 append 是 z
- append 过程 定义和两条 规则 都可以回答下面问题:
- 找出 (a b) 和 (c d) 的 append
- 然而这两条 规则 还可以回答下面问题(但 append 过程 不行):
- 找出一个表 y 使 (a b) 与它的拼接能得到 (a b c d)
- 找出所有拼接起来能得到 (a b c d) 的表 x 和 y
在逻辑式程序语言里,可以写出与上面两条规则直接对应的表达式,求值器可以基于它得到上述几个问题的解
各种逻辑语言(包括下面介绍的)都有缺陷,简单提供“做什么”知识
有时会使求值器陷入无穷循环或产生非用户希望的行为
演绎信息检索
逻辑式编程语言特别适合用作 数据库接口 ,完成 复杂的信息检索 。 查询语言 就是为此设计的,先用一个实例展示逻辑式编程的使用:
简单数据库
设 Microshaft 公司(位于波士顿的高科技公司)需要人事数据库,逻辑式语言不仅能做数据导向的信息访问,还能基于已有数据做推理
数据库内容是有关公司人事的断言,有许多描述各种事实的断言。Ben 是公司的计算机专家,关于他的断言如下:
(address (Bitdiddle Ben) (Slumerville (Ridge Road) 10)) (job (Bitdiddle Ben) (computer wizard)) (salary (Bitdiddle Ben) 60000)
- 在形式上,每个断言是一个表,其元素还可以是表
- 一个断言描述一个客观事实
Ben 管理公司的计算机分部,管理两个程序员和一个计算机技师:
(address (Hacker Alyssa P) (Cambridge (Mass Ave) 78)) (job (Hacker Alyssa P) (computer programmer)) (salary (Hacker Alyssa P) 40000) (supervisor (Hacker Alyssa P) (Bitdiddle Ben)) (address (Fect Cy D) (Cambridge (Ames Street) 3)) (job (Fect Cy D) (computer programmer)) (salary (Fect Cy D) 35000) (supervisor (Fect Cy D) (Bitdiddle Ben)) (address (Tweakit Lem E) (Boston (Bay State Road) 22)) (job (Tweakit Lem E) (computer technician)) (salary (Tweakit Lem E) 25000) (supervisor (Tweakit Lem E) (Bitdiddle Ben))
Hacker Alyssa 管着一个实习程序员:
(address (Reasoner Louis) (Slumerville (Pine Tree Road) 80)) (job (Reasoner Louis) (computer programmer trainee)) (salary (Reasoner Louis) 30000) (supervisor (Reasoner Louis) (Hacker Alyssa P))
计算机分部所有人员的职务的第一个符号都是 computer
Ben 是公司的高级雇员,其上司是公司大老板 Oliver:
(supervisor (Bitdiddle Ben) (Warbucks Oliver)) (address (Warbucks Oliver) (Swellesley (Top Heap Road))) (job (Warbucks Oliver) (administration big wheel)) (salary (Warbucks Oliver) 150000)
公司有一个财务分部,人员包括一个主管会计和一个助手:
(address (Scrooge Eben) (Weston (Shady Lane) 10)) (job (Scrooge Eben) (accounting chief accountant)) (salary (Scrooge Eben) 75000) (supervisor (Scrooge Eben) (Warbucks Oliver)) (address (Cratchet Robert) (Allston (N Harvard Street) 16)) (job (Cratchet Robert) (accounting scrivener)) (salary (Cratchet Robert) 18000) (supervisor (Cratchet Robert) (Scrooge Eben))
老板有一个秘书:
(address (Aull DeWitt) (Slumerville (Onion Square) 5)) (job (Aull DeWitt) (administration secretary)) (salary (Aull DeWitt) 25000) (supervisor (Aull DeWitt) (Warbucks Oliver))
还有一些断言说明各种人能从事的工作之间的关系:
- 计算机专家可以做程序员和技师的工作:
(can-do-job (computer wizard) (computer programmer)) (can-do-job (computer wizard) (computer technician))
- 程序员可以做实习程序员的工作:
(can-do-job (computer programmer) (computer programmer trainee))
- 秘书可以做老板的工作:
(can-do-job (administration secretary) (administration big wheel))
简单查询
要查询数据库里的信息,只需在提示符下输入查询。如:
;;; Query input: (job ?x (computer programmer)) ;;; Query results: (job (Hacker Alyssa P) (computer programmer)) (job (Fect Cy D) (computer programmer))
- 查询语句描述要 查询信息的模式 ,其中有些项是 具体信息 :
- 问号开头的模式变量 项(上面 ?x )可与任何东西匹配
- 系统响应查询时,给出 数据库里与查询模式 匹配的所有 条目
- 需要区分 多个匹配 和 同一匹配的多次 出现,因此 模式变量需要名字 :
(address ?x ?y) : 系统列出所有雇员的地址条目
- 如果查询中没有变量,就相当于问相应事实是否存在
- 同一模式变量可在一个查询里出现多次,表示需要 同一匹配 :
(supervisor ?x ?x) :要求给出所有自己管自己的雇员的条目
列出所有从事计算机工作的雇员:
(job ?x (computer ?type))
系统响应是:
(job (Bitdiddle Ben) (computer wizard)) (job (Hacker Alyssa P) (computer programmer)) (job (Fect Cy D) (computer programmer)) (job (Tweakit Lem E) (computer technician))
由于 ?type 只能匹配一个项,他不匹配:
(job (Reasoner Louis) (computer programmer trainee))
如果希望匹配第一个元素是 computer 的 所有条目 ,应写:
(job ?x (computer . ?type))
(computer . ?type) 能匹配 (computer programmer trainee) ,也能匹配 (computer technician) 和 (computer)
总结
- 设法找出使查询语句中的模式变量满足查询模式的所有赋值,即找出这些变量的所有可能指派(具体表达式),使得把模式中的变量代换为具体表达式后得到的条目在数据库里
- 对查询的响应是列出数据库里所有满足模式的条目,用找到的所有可能赋值对查询模式实例化,显示得到的结果
- 如果查询模式里无变量,就简化为对该查询是否出现在数据库里的检验。相应的赋值是空赋值
复合查询
简单查询是基本操作,可以在其基础上构造 复合查询 。查询语言的组合手段是连接词 and , or 和 not
注意:这些组合手段不是 Scheme 内部操作
对复合查询,系统也是 设法找出所有能满足它的赋值 ,并显示用这些赋值实例化查询模式得到的结果
and 查询
and 复合的一般形式:
(and <query1><query2> ... <queryn>)
要求找到的变量赋值满足 (and <query1><query2> … <queryn>) 中的 每个 查询。比如找出所有程序员的住址:
(and (job ?person (computer programmer)) (address ?person ?where))
返回的响应是:
(and (job (Hacker Alyssa P) (computer programmer))
(address (Hacker Alyssa P) (Cambridge (Mass Ave) 78)))
(and (job (Fect Cy D) (computer programmer))
(address (Fect Cy D) (Cambridge (Ames Street) 3)))
or 查询
or 复合的一般形式:
(or <query1><query2> ... <queryn>)
要求找出所有能满足 (or <query1><query2> … <queryn>) 之一 的赋值,给出用这些赋值实例化的结果。比如:得到由Ben Bitdiddle 或 Alyssa P. Hacker 管理的雇员名单:
(or (supervisor ?x (Bitdiddle Ben)) (supervisor ?x (Hacker Alyssa P)))
查询结果:
(or (supervisor (Hacker Alyssa P) (Bitdiddle Ben))
(supervisor (Hacker Alyssa P) (Hacker Alyssa P)))
(or (supervisor (Fect Cy D) (Bitdiddle Ben))
(supervisor (Fect Cy D) (Hacker Alyssa P)))
(or (supervisor (Tweakit Lem E) (Bitdiddle Ben))
(supervisor (Tweakit Lem E) (Hacker Alyssa P)))
(or (supervisor (Reasoner Louis) (Bitdiddle Ben))
(supervisor (Reasoner Louis) (Hacker Alyssa P)))
not 查询
not 查询的一般形式为:
(not <query>)
要求得到所有使 <query> 不成立 的赋值。比如,要求找出 Ben 管的所有人中的非程序员:
(and (supervisor ?x (Bitdiddle Ben)) (not (job ?x (computer programmer))))
lisp-value
lisp-value 的一般形式:
(lisp-value <predicate><arg1> ... <argn>)
第一参数 <predicate> 是一个Lisp 谓词。要求将 谓词作用于后面的参数 ( 赋值后得到的值 ), 选出使 谓词为真 的所有赋值。比如:选出所有工资高于 30000 的人
(and (salary ?person ?amount) (lisp-value > ?amount 30000))
利用 lisp-value 可以很灵活地描述各种查询
规则
查询语言的 抽象手段 是 建立规则 ,比如, 两个不同的人住得很近 的规则就是: 他们住在同一个town
(rule (lives-near ?person-1 ?person-2) (and (address ?person-1 (?town . ?rest-1)) (address ?person-2 (?town . ?rest-2)) (not (same ?person-1 ?person-2))))
同一个 表达成规则:
(rule (same ?x ?x))
组织里的大人物:如果被其管理的人还管别人
(rule (wheel ?person) (and (supervisor ?middle-manager ?person) (supervisor ?x ?middle-manager)))
规则的一般形式是:
(rule <conclusion> <body>)
其中 <conclusion> 是 模式 , <body> 是任何形式的 查询 。可以认为一条规则表示了很大(甚至无穷大)的一个断言集,其元素是 由 <conclusion>求出的所有满足<body> 的赋值
简单查询:
- 如果其中变量的某个赋值 满足某查询模式 ,那么用这个赋值实例化模式得到的断言一定在数据库里
- 但满足规则的断言不一定实际存在在数据库里,有可能是推导出的事实
比如,找出所有住在 Bitdiddle Ben 附近的雇员:
(lives-near ?x (Bitdiddle Ben))
返回结果:
(lives-near (Reasoner Louis) (Bitdiddle Ben)) (lives-near (Aull DeWitt) (Bitdiddle Ben))
找出所有住在 Bitdiddle Ben 附近的程序员:
(and (job ?x (computer programmer)) (lives-near ?x (Bitdiddle Ben)))
与复合过程类似, 已定义的规则可以用于定义新规则 。例如:
(rule (outranked-by ?staff-person ?boss) (or (supervisor ?staff-person ?boss) (and (supervisor ?staff-person ?middle-manager) (outranked-by ?middle-manager ?boss))))
这是一条递归定义的规则:
- 一个职员是某老板的下级
- 如果该老板是其主管,或者(递归的)其主管是该老板的下级
逻辑程序
规则可看作 逻辑蕴涵式 : 若对 所有模式变量的赋值能满足一条规则的身体 ,那么它就满足其结论。查询语言就是 基于规则做逻辑推理
考虑 append 的例子,描述它的规则说:
- 对任何表 y,空表与它 append 得到的就是 y 本身
- 对任何表 u, v, y, z,(cons u v) 与 y 的 append 是 (cons u z) 的条件:v 与 y 的 append 是 z
用查询语言描述,需要 描述关系 (append-to-form x y z) ,直观解释是 “x 和 y 的拼接得到 z”。用规则定义是:
(rule (append-to-form () ?y ?y)) (rule (append-to-form (?u . ?v) ?y (?u . ?z)) (append-to-form ?v ?y ?z))
- 第一条规则 没有体 ,说明它 对任何 y 成立
- 第二条规是 递归定义 的
- 注意:这里用了表的 点号 形式
有了上面有关 append-to-form 的规则,可以做许多查询:
'(a b) 和 '(c d) 做 append 的结果
;;; Query input: (append-to-form (a b) (c d) ?z) ;;; Query results: (append-to-form (a b) (c d) (a b c d))
什么和 '(a b) 做 append 会返回 '(a b c d)
;;; Query input: (append-to-form (a b) ?y (a b c d)) ;;; Query results: (append-to-form (a b) (c d) (a b c d))
x 和 y 做 append 会返回 '(a b c d), x, y 的值是什么:
;;; Query input: (append-to-form ?x ?y (a b c d)) ;;; Query results: (append-to-form () (a b c d) (a b c d)) (append-to-form (a) (b c d) (a b c d)) (append-to-form (a b) (c d) (a b c d)) (append-to-form (a b c) (d) (a b c d)) (append-to-form (a b c d) () (a b c d))
设计
显然查询求值器要搜索,设法将查询与数据库里的事实和规则匹配
- 可参考 amb ,将系统实现为一个非确定性程序
- 可以借用 流 的概念控制搜索。这里采用基于流的技术
查询系统的组织围绕两个核心操作:
- 模式匹配 :系统实现 简单查询 和 复合查询 ,要考虑它与 基于流的信息 的 集成
- 合一 : 模式匹配的推广 ,用于 实现规则
最后讨论如何通过 表达式的分情况处理 , 构造整个的 查询解释器
模式匹配
查询系统的基本构件包括一个匹配器, 模式匹配 是其基本操作。模式匹配器 检查一个数据项是否与某个给定模式匹配 ,比如: 数据表 ((a b) c (a b)) :
- 与模式 (?x c ?x) 匹配,其中模式变量 ?x 约束于 (a b)
- 与模式 (?x ?y ?z) 匹配,其中 ?x 和 ?z 都约束到 (a b) , ?y 约束到 c
- 与模式 ((?x ?y) c (?x ?y)) 匹配,其中的 ?x 约束到 a , ?y 约束到 b
- 与模式 (?x a ?y) 不匹配,因这个模式要求表中第二个元素必须是 a
由此可见,一个框架记录了一组模式变量与其当时确定的约束
模式匹配器以一个 模式 、一个 数据 和一个 框架 为输入。它 检查 数据 是否以某种 方式 与 模式 匹配 ,而且该 匹配 与 框架 里已有的 约束 相容(不矛盾)
- 匹配 成功 时返回 原框架的扩充 ,加入 新确定的所有约束
- 匹配 失败 时返回一个 失败信息
基于 空框架 用模式 (?x ?y ?x) 匹配 _(a b a) ,匹配器返回的框架里 ?x 约束到 a , ?y 约束到 b
如果用同一模式、同一数据和包含 ?y 约束到的 a 框架去匹配,这个匹配将 失败
如果用同一模式、同一数据和包含 ?y 约束到的 b 框架去匹配,匹配器返回的框架 扩充 了 ?x 到 a 的约束
模式匹配器处理 所有不涉及 规则 的查询 。如,输入查询 (job ?x (computer programmer))
- 匹配器将从一个 空框架 出发 扫描数据库里的断言 ,选出其中与这个模式匹配的断言,得到相应的匹配框架(流)
- 对于每个成功的匹配,语言的求值器都用匹配器返回的各个框架里 ?x 的值实例化上述模式 ,得到最终结果
简单查询
匹配器采用 流 的方式,基于给定 框架 做模式匹配:
- 基于给定框架 扫描 数据库断言。对每个 断言
- 产生表示匹配 失败的特殊符号
- 给出原框架的一个 扩充 , 匹配 结果形成一个流
- 用一个 过滤器 删除匹配失败信息 ,结果流里包含的框架都是 原框架由于断言匹配而得到的扩充
一个查询以一个 框架流 作为输入,基于流中每个框架做上述匹配, 合并 产生的 所有框架流 ,得到作为 查询结果的输出流
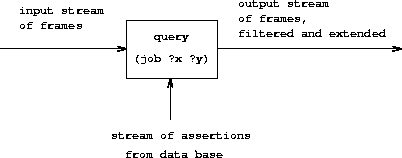
回答简单查询时,初始输入流里只有一个 空框架 ,得到的流包含这一空框架的 所有扩充 。用这个流 实例化查询模式 ,就能得到所有输出:
and 查询
处理复合查询时,利用匹配器 带着框架 去检查匹配的功能。例如:
(and (can-do-job ?x (computer programmer trainee)) (job ?person ?x))
先找出与模式 (can-do-job ?x (computer programmer trainee)) 匹配的 框架流 ,其中每个框架都包含对 ?x 的 约束项 。再找所有与模式 (job ?person ?x) 匹配的项,其匹配与给定的 ?x 匹配一致。作为结果的流中各框架都包含了 ?person 和 ?x 的 约束 。下图显示了 and 查询的处理过程:
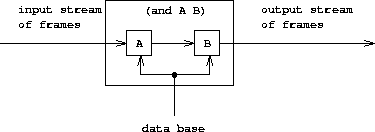
框架流顺序地通过两个查询,最终得到结果流
处理复合查询的效率问题:
一步查询中,对输入流里的每个框架都可能产生多个框架,一系列 and 查询里的每个查询都是从前一个查询得到框架流
这使 and 查询中可能的匹配次数是查询个数的指数函数
or 查询
两个查询的 or 是 两个查询分别得到的 框架流的归并 ,归并可以采用 交错 方式:
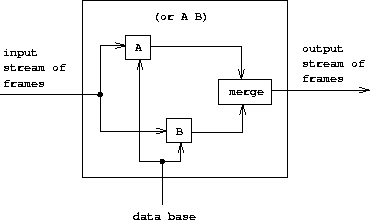
not 查询
断言 q 的 not 是一个 框架过滤器 ,删除流中所有满足 q 的框架。例如:
(not (job ?x (computer programmer)))
对空框架生成满足 (job ?x (computer programmer) 的扩充。如果一个框架能扩充就丢掉它。不能产生扩充的留在输出流里
(and (supervisor ?x ?y) (not (job ?x (computer programmer))))
- and 的第一个子句生成一批带有 ?x 和 ?y 的约束的框架
- 后面的 not 子句 删除 所有使 ?x 的工作是程序员的框架
lisp-value 查询
实现为框架流的 过滤器 :
- 用流中框架 实例化模式的变量
- 对 实例化结果应用给定谓词 , 删去 不满足谓词的框架
合一
在处理 规则 时,要 找出其结论与被处理查询模式匹配的所有规则 。结论_ 的形式很像 断言 ,但是它可以 包含变量 :
- 匹配的两边( 查询模式 和 规则的结论 )都可以 有变量
- 模式匹配 只允许一方有变量
合一 是 模式匹配的扩充 ,它 判断 两个模式 之间能否匹配 。工作方式:
- 设法确定是否 存在一组变量赋值 ,使得这 两个模式经过赋值的实例化 后得到的 表达式相同
- 成功时返回得到的赋值(框架)
- 返回失败信息
对 (?x a ?y) 和 (?y ?z a) 的合一操作将产生一个框架,在框架里 ?x, ?y 和 ?z 都约束到 a
对 (?x ?y a) 和 (?x b ?y) 的合一将会失败,因为对 ?y 的任何赋值都不能使两个模式相同
根据模式的第二个元素 ?y 应约束到 b
然而根据它们的第三个元素 ?y 又应约束到 a
合一算法是整个查询系统实现的难点。完成两个复杂模式的合一,看起来好像需要做 推理 :
合一 (?x ?x) 和 ((a ?y c) (a b ?z)) ,可以得到一个联立方程: ?x = (a ?y c) ?x = (a b ?z) 它等价于 (a ?y c) = (a b ?z) 它蕴涵着 a= a,?y= b,c= ?z 继续做下去,可得 ?x = (a b c)
- 模式匹配成功将给所有变量赋值,前面例子都是赋值为常量的情况
- 成功的合一可能产生 变量值不能完全确定 的情况:
- 可能出现 未约束的变量
- 变量 约束的值里也可能还包含变量
考虑 (?x a) 和 ((b ?y) ?z) 合一得到 ?x = (b ?y) ,?z = a
但 ?x 和 ?y 的值不能确定。这时也认为成功,因为已经可以确定 ?x 和 ?y 的赋值了
这里 ?y 取值没限制,但 ?x 必须是 (b ?y)。应把 ?x 到 (b ?y) 的约束放入框架
如果后来?y 值确定,?x 就引用相应的值
最一般的合一确实需要解方程。但这里情况比较简单,可直接处理
规则应用
假设要处理下面的规则:
(lives-near ?x (Hacker Alyssa P))
- 先用 模式匹配 到数据库里找匹配断言:找不到
- 再做与 规则结论的合一 ,发现它与下面规则合一成功:
(rule (lives-near ?person-1 ?person-2) (and (address ?person-1 (?town . ?rest-1)) (address ?person-2 (?town . ?rest-2)) (not (same ?person-1 ?person-2))))
- 得到 ?person-2 约束到 (Hacker Alyssa P) , ?x 约束到 ?person-1
- 然后 基于此框架 对 规则体的复合查询 求值。匹配成功时 ?person-1 将建立约束,从而也给 ?x 建立了约束
当求值器在基于一个框架完成对某个查询模式的匹配时,尝试 应用一条规则 的过程是:
- 将 查询模式与规则的结论合一 ,成功时 形成原框架的一个扩充
- 基于这样扩充的框架 再去 求值该规则的体 ,这实际上又是一个 查询
这一做法很像 Lisp 的 eval/apply 求值器中的过程应用: 1. 将过程的形式参数约束于实际参数值,用得到的框架扩充原环境 2. 基于扩充后的环境去求值过程体 这种相似也很自然: 过程定义是 Lisp 里的抽象手段 规则定义是查询语言里的抽象手段 无论是应用过程还是应用规则,都需要打开相关的抽象,就是建立相应约束,而后基于它们去求值过程或者规则的体
简单查询
使用 规则 和 断言 求值 简单查询 的完整过程:
- 给定一个 查询模式 和一个 框架流 ,对流中每个框架产生 两个流 :
- 模式匹配器 :用 给定模式 与 数据库断言 匹配 ,得到 扩充框架的流
- 合一器 : 应用 所有 可用的规则 ,得到另一个 扩充框架的流
- 归并 为与 原框架相容 的 满足 给定模式 的 所有扩充框架 的流
- 把处理给定框架流里各个框架得到的流组合为一个流,其中包含由输入流中各框架扩充而得到的与给定模式匹配的所有结果
这样的系统很像一般语言的求值器,只是其中的匹配操作比较复杂
查询求值器
过程 qeval 协调各种匹配操作,起着类似 eval 的作用:
- 参数是一个 查询 和一个 框架流
- 结果是一个 框架流 ,其中包含所有 成功匹配得到的扩充框架
- qeval 根据查询的类型分情况处理,将请求分派到对应的过程
- 简单查询
- and
- or
- not
- lisp-value
驱动循环
驱动循环 由 终端 取得输入:
- 用得到的查询和一个 空框架 的流 调用 qeval
- 用 qeval 返回的流中的每个框架去实例化原查询
- 最后打印出实例化的结果
驱动循环还支持特殊命令 assert!
- 该命令说明输入不是 查询 而是一条 断言或规则
- 这种情况下,把相应 的断言或规则加入数据库
(assert! (job (Bitdiddle Ben) (computer wizard))) (assert! (rule (wheel ?person) (and (supervisor ?middle-manager ?person) (supervisor ?x ?middle-manager))))
数理逻辑
查询语言的组合符对应于各逻辑连接词,查询的做法看起来也具有逻辑可靠性(and 查询要经过两个子成分处理,等等),但这种对应关系并 不严格 ,因为查询语言的基础是求值器,其中隐含着 控制结构 和 控制流程 ,是用 过程的方式解释逻辑语句
当然这种控制结构也可以利用例如要找程序员的上司,下面写法都行:
(and (job ?x (computer programmer)) (supervisor ?x ?y)) (and (supervisor ?x ?y) (job ?x (computer programmer)))
如果公司里的上司比程序员多,第一种写法的查询效率更高
逻辑程序设计的目标是开发一种技术,把计算问题分为两个相互独立的子问题:需要计算 什么 和怎样_ 计算。途径是:
- 找出逻辑语言的一个子集
- 其功能 足够强 ,足以 描述人们想考虑的某类计算
- 足够弱,有可能为 它定义一种过程式的解释
- 实现一个 求值器 (解释器),执行对用这种逻辑子集写出的 规则和断言的解释 (实现其语义)
前面描述的查询语言是上面想法的一个具体实施:
查询语言 是数理逻辑的一个可以 过程式解释的子集
一个 断言 描述了一个简单 事实
一条 规则 表示一个 蕴涵 ,所有使规则体成立的情况都使结论成立
规则有自然的过程式解释:要得到其结论,只需确定其体成立
上述两方面性质保证逻辑程序设计语言程序的有效性:
- 用这种语言写出的一组规则实际上描述了一个计算过程
- 写出的断言可以交给计算机执行(说明式的描述)
- 具体的控制流程交给语言背后的求值器处理(过程式的执行)
由于规则是逻辑语句,有逻辑解释。因此可以做些逻辑工作:
检查逻辑推理是否总能得到同样的结果
如果确实如此,就确认了求值器的可靠性
执行具有过程式的特征:
- 程序员可以通过安排子句的顺序和各子句中子目标的顺序控制计算过程。如果安排得好,有可能得到更高效的计算
- 由于用逻辑式程序的过程性解释,因此可能写出很低效的程序
极端情况是有关程序使相应的解释陷入无穷循环
无穷循环
假定要做一个有关著名婚姻的数据库,加入断言:
(assert! (married Minnie Mickey))
查询 (married Mickey ?who) 得不到结果。因为系统不知道婚姻是 相互的 (对称的)
如果加入规则:
(assert! (rule (married ?x ?y) (married ?y ?x)))
再查询时系统将陷入无穷循环:
该规则产生的框架里 ?x 约束到 Mickey,?y 约束到 ?who
规则体要求基于得到的框架匹配 (married ?who Mickey)。但这一查询不但与事实匹配,而且还与上面的规则匹配
不幸的是由规则体得到的查询还是(married Mickey ?who),使系统进入无穷循环
- 能不能在进入无穷循环前找到匹配的断言 依赖于查询的实现细节
- 一组相关规则也可能导致无穷循环
not 问题
对前面数据库做下面两个查询:
(and (supervisor ?x ?y) (not (job ?x (computer programmer)))) (and (not (job ?x (computer programmer))) (supervisor ?x ?y))
与逻辑里的情况不同,这两个查询会得到不同结果
- 第一个查询找出所有与 (supervisor ?x ?y) 匹配的条目,从得到的框架中删去 ?x 满足 (job ?x (computer programmer)) 的框架
- 第二个查询从初始框架流(只含一个空框架)开始检查能否扩展出与 (job ?x (computer programmer)) 匹配的框架。显然空框架可扩展, not 删除流中的空框架 得到 空流 ,查询最后返回 空流
出问题的原因是对 not 的解释: 这里把 not 模式看作一种过滤器,如果 not 作用时模式里有未约束变量,就会产生不希望的结果 lisp-value 也有类似问题。如果使用lisp-value 的谓词时有些参数没有约束,系统显然无法正常工作
此外, 查询语言 里的 not 与 逻辑 里的 not 还有一个本质差异:
- 逻辑里 not P 的意思是 P 不真
- 查询系统里 not P 则是说 P 不能由数据库里的知识推导出来 。例如,从前面的人事数据库可以推导出许多 not 断言:
- Ben Bitdiddle 不喜欢打篮球
- 外面没有下雨
- 2 + 2 不等于 4
- …….
逻辑程序语言里的 not 反映的是一种“封闭世界假说”,认为所有知识都包含在数据库里,凡是没有的东西其 not 都成立
显然这并不符合形式化的数理逻辑,也不符合人们的直观推理
实现
驱动循环和实例化
- 查询系统的驱动循环反复读输入表达式:
- 如果是 断言 或 规则 ,就把相关信息 加入数据库
- 否则认为是 查询 ,送给 qeval ,并送去一个 流 ,其中只包含一个 空框架
- 求值查询 得到一个 框架流 :
- 各框架里的项说明 模式中变量 的 约束值
- 用框架流中的框架对 模式做实例化 ,得到 实例化结果的流
- 输出流中的各项,这是一些 简单或复合的断言
(define (query-driver-loop) (prompt-for-input input-prompt) (let ((q (query-syntax-process (read)))) (cond ((assertion-to-be-added? q) (add-rule-or-assertion! (add-assertion-body q)) ; 加入断言或规则 (newline) (display "Assertion added to data base.") (query-driver-loop)) ; 重启主循环 (else (newline) (display output-prompt) (display-stream (stream-map (lambda (frame) (instantiate q ; 用结果流中的框架 frame 做查询模式q 的实例化 frame (lambda (v f) ; f 的实参是 frame (contract-question-mark v)))) ;处理未约束变量,产生适当的输出形式 (qeval q (singleton-stream '())))) ; 从包含一个空框架的流查询出匹配的框架流 (query-driver-loop))))) ; 重启主循环
- query-syntax-process : 处理输入表达式前将其变换为一种易处理形式, 修改其中变量的表示
- contract-question-mark : 查询后打印前把 未约束变量变回原形式
- 实例化 表达式时需要 复制 ,用给定 框架 里的 约束 代换 其中的 变量
(define (instantiate exp frame unbound-var-handler) (define (copy exp) ; 使用 frame 里的约束构造 exp 的实例化副本 (cond ((var? exp) (let ((binding (binding-in-frame exp frame))) (if binding (copy (binding-value binding)) (unbound-var-handler exp frame)))) ; 用传入的 过程参数 来 处理未约束变量 ((pair? exp) (cons (copy (car exp)) (copy (cdr exp)))) (else exp))) (copy exp))
无约束变量用 instantiate 的参数 unbound-var-handler 处理
例如,变量 ? x 和 exp 合一操作后得到其值为 ? y,而 ? y 被约束为 5
对于这个未约束变量 ? x 将使用传递进 instantiate 的参数过程来处理
求值器
qeval-driver-loop 调用基本求值过程 qeval ,qeval 是查询求值器的 核心 :
- 参数是一个 查询模式 和一个 框架流
- 返回 扩充后的框架流
qeval 用 type 识别各种 特殊形式 ,基于 get 和 put 组织操作 ,根据类型完成 数据导向 的分派:
(define (qeval query frame-stream) (let ((qproc (get (type query) 'qeval))) (if qproc (qproc (contents query) frame-stream) ; 如果是特殊处理过程,就用该过程处理 (simple-query query frame-stream)))) ; 非特殊形式的表达式都当作简单查询
type 和 contents 是 语法过程 ,后面会定义
简单查询
simple-query :处理简单查询
- 参数是一个 模式 和一个 框架流
- 它逐个处理流中各框架:
- find-assertions : 找数据库里的 匹配断言 ,生成 扩充框架的流
- apply-rules : 应用可应用的规则 ,生成 扩充框架的流
- stream-append-delayed : 组合 上面两个流
- stream-flatmap : 把处理各框架得到的流 合并为一个流 ( 平坦化 )
(define (simple-query query-pattern frame-stream) (stream-flatmap ; 把处理各框架得到的流合并为一个流 (lambda (frame) (stream-append-delayed ; 组合两个流 (find-assertions query-pattern frame) ; 找数据库里的匹配断言,生成扩充框架的流 (delay (apply-rules query-pattern frame)))) ; 应用可应用的规则,生成扩充框架的流 frame-stream))
这里用到了 流的延时 处理
复合查询
and 查询
过程 conjoin 处理 and 查询:
- 参数是 合取项的表 和一个 框架流 。允许 任意多个 合取项
- conjoin 递归地使用各个合取项 基于处理 第一个合取项得到的框架流 去处理其他合取项:
(define (conjoin conjuncts frame-stream) (if (empty-conjunction? conjuncts) frame-stream (conjoin (rest-conjuncts conjuncts) (qeval (first-conjunct conjuncts) frame-stream))))
为使 qeval 能使用 conjoin ,需要将它设置好:
(put 'and 'qeval conjoin)
or查询
过程 disjoin 处理 or 查询:
- 参数是一些 析取项 和一个 框架流
- 用各个析取项去扩充框架流里的框架,最后 归并得到的流 需要用 交错 的方式做(用 interleave-delayed )
(define (disjoin disjuncts frame-stream) (if (empty-disjunction? disjuncts) the-empty-stream (interleave-delayed (qeval (first-disjunct disjuncts) frame-stream) (delay (disjoin (rest-disjuncts disjuncts) frame-stream))))) (put 'or 'qeval disjoin)
两个分支分别处理 第一个析取项 和 其余的析取项
过滤器
not 过滤器
设法扩充输入流中每个框架,看它能否满足作被not 否定的模式:
(define (negate operands frame-stream) (stream-flatmap (lambda (frame) (if (stream-null? (qeval (negated-query operands) ; 逆条件查询 (singleton-stream frame))) ; 框架流中的某个框架是否满足 逆查询 (singleton-stream frame) ; 满足的话,加入结果流 the-empty-stream)) ; 不满足的话,过滤掉 frame-stream)) (put 'not 'qeval negate)
lisp-value 过滤器
lisp-value 的工作方式与 not 类似:
- 流中各 框架去实例化模式里的变量
- 将 谓词应用于这些变量
- 丢掉 使 谓词返回假 的 框架
- 遇到 未约束的变量 就是 错误
(define (lisp-value call frame-stream) ; call 被应用的谓词 (stream-flatmap (lambda (frame) (if (execute ; 处理实例化后的谓词,类似于 eval,但不求值谓词的参数(因它们已经是值) (instantiate ; instantiate 用 frame 实例化 call 里的变量,得到所需的谓词表达式 call frame (lambda (v f) (error "Unknown pat var -- LISP-VALUE" v)))) ; 遇到未约束的变量,就是错误 (singleton-stream frame) the-empty-stream)) frame-stream)) (put 'lisp-value 'qeval lisp-value)
- instantiate 用 frame 实例化 call 里的变量,得到所需的 谓词表达式
- execute 将 谓词应用于实际参数
- 通过基础的 eval 和 apply 实现,将 exp 里的 谓词作用于参数
(define (execute exp) (apply (eval (predicate exp) user-initial-environment) (args exp)))
与eval 不同,谓词作用的对象已是值,不需要再次求值
always-true
特殊形式 always-true 描述 总能满足的查询 ,忽略查询内容, 直接返回作为参数的框架流 :
(define (always-true ignore frame-stream) frame-stream) (put 'always-true 'qeval always-true)
与 not 和 lisp-value 有关的语法过程( 选择函数 )在后面定义
模式匹配
简单查询调用 find-assertion ,返回将参数 frame 与 数据 匹配得到的 框架形成的流 。其中:
- fetch-assertions 返回数据库中断言的流
- 用 pattern 和 frame 做 简单检查 , 丢掉明显不可能匹配的断言
(define (find-assertions pattern frame) (stream-flatmap (lambda (datum) (check-an-assertion datum pattern frame)) ; 丢掉不可能匹配的断言 (fetch-assertions pattern frame))) ; 从数据库获取断言的流
check-an-assertion : 对一个 断言 调用 匹配过程
- 成功时:返回包含 一个扩充框架的流
- 不成功:返回 空流
(define (check-an-assertion assertion query-pat query-frame) (let ((match-result (pattern-match query-pat assertion query-frame))) ; 调用匹配器 (if (eq? match-result 'failed) the-empty-stream ; 失败返回空流 (singleton-stream match-result)))) ; 成功包含 一个扩充框架的流
基本匹配器
pattern-match 是 基本匹配器 :
- 匹配失败:返回符号 failed
- 成功返回: 扩充的框架
这里按 结构递归地匹配 :
(define (pattern-match pat dat frame) (cond ((eq? frame 'failed) 'failed) ((equal? pat dat) frame) ; 相同时,匹配成功,直接返回原框架 ((var? pat) (extend-if-consistent pat dat frame)) ; 模式是个变量,基于 frame 和新约束做扩充,检查是否协调 ((and (pair? pat) (pair? dat)) (pattern-match (cdr pat) ; 递归匹配模式和数据的cdr 部分 (cdr dat) (pattern-match (car pat) (car dat) frame))) ; 以匹配 car 部分得到的可能,扩充的框架作为框架 (else 'failed)))
- extend-if-consistent
(define (extend-if-consistent var dat frame) (let ((binding (binding-in-frame var frame))) ; 找出 var 在 frame 里的约束 (if binding (pattern-match (binding-value binding) dat frame) ; 检查是否匹配 (extend var dat frame)))) ; var 无约束,把新约束加入frame
- 在 var 和 dat 的 约束 与 frame 里的 约束 兼容 时产生扩充的框架
- 如果 var 在 frame 里已有约束,只有 这一 约束 和现数据 dat 匹配 时,整个匹配才成功
- (binding-value binding) : 取出的已有匹配里还可能有变量 (由 合一得到的约束 )
目前框架里 ?x 约束到 (f ?y) 而 ?y 无约束,现在想加入 ?x 与 (f b) 的约束来扩大框架
这一过程在框架里查找 ?x ,并发现它已约束到 (f ?y)
这导致要在同一框架里做(f ?y) 与新值 (f b) 的匹配,最终将 ?y 到 b 的约束加入框架
变量 ?x 仍约束到 (f ?y)
匹配中已有的约束绝不改变,也不会出现一个变量有多个约束的情况
点号模式
如果模式中有 圆点 ,圆点后面应是一个模式变量,该变量将与数据表的 剩下部分 匹配(而不是与 下一元素 匹配)
虽然在模式匹配器没专门处理圆点,但却能正确工作
因为模式和数据都用 Scheme 的表表示,圆点自然有合适意义
read 读查询时遇到圆点就把下一个项作为所构造表达式的 cdr。例如:
- 读入模式 (computer ?type) ,read产生的表结构相当于对表达式 (cons 'computer (cons '?type '())) 求值产生的结构
- 读入模式 (computer . ?type) 时,产生的结构相当于对表达式 (cons 'computer '?type) 求值产生出的结构
如果匹配器用模式 (computer . ?type) 去匹配,它将用 ?type 与数据的 cdr 部分匹配
例如与 (computer programmer trainee) 匹配时,?type 将约束到 (programmer trainee)
规则合一
应用规则
apply-rules :应用规则,以一个 模式 和一个 框架 为输入,生成一个 框架流 。它被 simple-query 调用
(define (apply-rules pattern frame) (stream-flatmap (lambda (rule) (apply-a-rule rule pattern frame)) (fetch-rules pattern frame)))
apply-a-rule : 应用一条规则
(define (apply-a-rule rule query-pattern query-frame) (let ((clean-rule (rename-variables-in rule))) ; 规则里的变量统一改名,使之不会与其他规则冲突 (let ((unify-result (unify-match query-pattern (conclusion clean-rule) query-frame))) ; 做查询模式和规则结论做合一匹配 (if (eq? unify-result 'failed) the-empty-stream (qeval (rule-body clean-rule) (singleton-stream unify-result)))))) ; 基于得到的 新框架流 做 规则体 的匹配
rename-variables-in rule : 构造新的“干净”规则
(define (rename-variables-in rule) (let ((rule-application-id (new-rule-application-id))) (define (tree-walk exp) (cond ((var? exp) (make-new-variable exp rule-application-id)) ((pair? exp) (cons (tree-walk (car exp)) (tree-walk (cdr exp)))) (else exp))) (tree-walk rule)))
递归遍历该规则,重命名所有变量(加唯一编号后缀)
每次应用规则前重新构造一个“干净”规则,比较耗时
合一操作
合一的不同点就在于 匹配的两边都可能有变量 ,因此都可能建立约束。与简单匹配的仅有差异在对变量的处理:
(define (unify-match p1 p2 frame) (cond ((eq? frame 'failed) 'failed) ((equal? p1 p2) frame) ((var? p1) (extend-if-possible p1 p2 frame)) ; 两边都可能是变量 ((var? p2) (extend-if-possible p2 p1 frame)) ((and (pair? p1) (pair? p2)) (unify-match (cdr p1) (cdr p2) (unify-match (car p1) (car p2) frame))) (else 'failed)))
遇变量时要考虑两种情况,由 extend-if-possible 完成
- 如果 另一方也是变量 ,则需考虑它 是否已有约束
- 如果有,就让 被处理变量取相同约束
- 否则就直接将其 约束于另一方变量
- 如果要将 变量约束于一个模式 ,而 模式里有这个变量 。那么 任何赋值都不可能实现这一匹配 ,应作为匹配失败
两模式里都有重复变量,可能出现第二种情况
匹配 (?x ?x) 和 (?y (a ?y))。先得到了 ?x 约束于 ?y
下面要用 ?x 匹配 (a ?y)
由于 ?x 约束于 ?y,因此要匹配 ?y 和 (a ?y)
显然这一匹配不可能成功
(define (extend-if-possible var val frame) (let ((binding (binding-in-frame var frame))) (cond (binding (unify-match (binding-value binding) val frame)) ; 若var 已有约束,要求其约束值可与 val 合一 ((var? val) ; 匹配的另一方也是变量。如果该变量有约束,则要求 var 可与该变量的约束值合一 (let ((binding (binding-in-frame val frame))) (if binding (unify-match var (binding-value binding) frame) (extend var val frame)))) ((depends-on? val var frame) ; val 依赖于 var 时匹配失败 'failed) (else (extend var val frame)))))
depends-on? 检查一个 表达式 是否依赖 于一个变量 ?x 。这一检查也需要相对于一个 frame 进行,因为可能在模式里出现另一变量 ?y ,而 ?y 在 frame 里的 约束 依赖 于 ?x (还可能继续传递)
(define (depends-on? exp var frame) (define (tree-walk e) (cond ((var? e) ; 是变量 (if (equal? var e) ; 和 var 相同 true (let ((b (binding-in-frame e frame))) ; b 是 e 在 frame 里的约束 (if b (tree-walk (binding-value b)) ; 检查约束值 是否有依赖 false)))) ((pair? e) ; 递归检查每个序对的 car 和 cdr (or (tree-walk (car e)) (tree-walk (cdr e)))) (else false))) (tree-walk exp))
这一检查基本是按结构递归
数据库操作
断言表示
数据库维护的关键是尽可能 减少检索时需考察的断言 :
- 先把 所有断言 存入一个大流
- 把 car 部分是相同常量的断言 存入同一个流,以 该 car 为索引 把流存入一个表格(另一关键码用 assertion-stream )
(define THE-ASSERTIONS the-empty-stream) (define (fetch-assertions pattern frame) (if (use-index? pattern) ; pattern 的 car 是常量 (get-indexed-assertions pattern) ; 到特定的流里去检索 (get-all-assertions))) (define (get-all-assertions) THE-ASSERTIONS) (define (get-indexed-assertions pattern) (get-stream (index-key-of pattern) 'assertion-stream))
get-stream : 按 key1 和 key2 到表格里找相应流,找不到时返回空流
(define (get-stream key1 key2) (let ((s (get key1 key2))) (if s s the-empty-stream)))
规则表示
规则管理的方式类似,以规则中 结论部分的car 为索引 ,将结论的 car 相同的规则的流存入表格(另一关键码是 rule-stream )
(define THE-RULES the-empty-stream) (define (fetch-rules pattern frame) (if (use-index? pattern) (get-indexed-rules pattern) (get-all-rules))) (define (get-all-rules) THE-RULES)
car 是常量的模式 可与 结论的 car 相同的规则 匹配,也与 结论的 car 是变量的规则 匹配。为方便处理, 所有结论的 car 是变量的规则存入 ?索引 的流 。与 car 部分是常量的模式匹配的流可能由两个流组成:
(define (get-indexed-rules pattern) (stream-append (get-stream (index-key-of pattern) 'rule-stream) (get-stream '? 'rule-stream))) ; 所有结论的 car 是变量的规则存入 ?索引 的流
添加操作
加入断言或规则的请求分情况处理:
- 不但将它加入 包含所有断言或规则的主流
- 还根据其(或结论)的 car 加入 表格里的支流
(define (add-rule-or-assertion! assertion) (if (rule? assertion) (add-rule! assertion) (add-assertion! assertion))) (define (add-assertion! assertion) (store-assertion-in-index assertion) (let ((old-assertions THE-ASSERTIONS)) (set! THE-ASSERTIONS (cons-stream assertion old-assertions)) 'ok)) (define (add-rule! rule) (store-rule-in-index rule) (let ((old-rules THE-RULES)) (set! THE-RULES (cons-stream rule old-rules)) 'ok))
加入支流的工作由两个专门过程完成:
(define (store-assertion-in-index assertion) (if (indexable? assertion) (let ((key (index-key-of assertion))) (let ((current-assertion-stream (get-stream key 'assertion-stream))) (put key 'assertion-stream (cons-stream assertion current-assertion-stream))))))
(define (store-rule-in-index rule) (let ((pattern (conclusion rule))) (if (indexable? pattern) (let ((key (index-key-of pattern))) (let ((current-rule-stream (get-stream key 'rule-stream))) (put key 'rule-stream (cons-stream rule current-rule-stream)))))))
可以加入某个支流的 条件 :
- 模式的 car 是常量符号
- 对于 规则 ,还有其 结论(模式)的 car 是模式变量 的情况:
(define (indexable? pat) (or (constant-symbol? (car pat)) ; 模式的 car 是常量符号 (var? (car pat)))) ; 模式(结论)的 car 是模式变量
- 模式存入表格用的 关键码 就是 其 car
- 对于规则的结论模式,如果 其 car 是模式变量 ,关键码用 ? :
(define (index-key-of pat) (let ((key (car pat))) (if (var? key) '? key)))
如 模式的 car 是常量符号 ,就用 它作为索引 去提取相应的流用于检索:
(define (use-index? pat) (constant-symbol? (car pat)))
流操作
查询系统用了几个前面没定义的流操作:
- append
(define (stream-append-delayed s1 delayed-s2) (if (stream-null? s1) (force delayed-s2) (cons-stream (stream-car s1) (stream-append-delayed (stream-cdr s1) delayed-s2))))
- 交错归并:
(define (interleave-delayed s1 delayed-s2) (if (stream-null? s1) (force delayed-s2) (cons-stream (stream-car s1) (interleave-delayed (force delayed-s2) (delay (stream-cdr s1))))))
- 把过程 proc 用于 s 的每个元素后将得到的流 平坦化 :
(define (stream-flatmap proc s) (flatten-stream (stream-map proc s))) (define (flatten-stream stream) (if (stream-null? stream) the-empty-stream (interleave-delayed (stream-car stream) (delay (flatten-stream (stream-cdr stream))))))
- 构造只包含一个元素的流:
(define (singleton-stream x) (cons-stream x the-empty-stream))
语法过程
类型表达式
应该是 表 ,其 类型 就是其 第一个元素 ,其 内容 就是 去掉第一个元素之后的那个表 :
(define (type exp) (if (pair? exp) (car exp) (error "Unknown expression TYPE" exp))) (define (contents exp) (if (pair? exp) (cdr exp) (error "Unknown expression CONTENTS" exp)))
断言
断言的类型是 assert ,其 内容 就是 表的第二个元素 :
在基本驱动循环里用 (assert! <rule-or-assertion>)
(define (assertion-to-be-added? exp) (eq? (type exp) 'assert!)) (define (add-assertion-body exp) (car (contents exp)))
组合断言 的语法过程:
;;; and (define (empty-conjunction? exps) (null? exps)) (define (first-conjunct exps) (car exps)) (define (rest-conjuncts exps) (cdr exps)) ;;; or (define (empty-disjunction? exps) (null? exps)) (define (first-disjunct exps) (car exps)) (define (rest-disjuncts exps) (cdr exps)) ;;; not (define (negated-query exps) (car exps)) ;;; lisp-value (define (predicate exps) (car exps)) (define (args exps) (cdr exps))
规则
(define (rule? statement) (tagged-list? statement 'rule)) (define (conclusion rule) (cadr rule)) ; 结论 (define (rule-body rule) (if (null? (cddr rule)) '(always-true) (caddr rule))) ; 规则的体
把模式中的 模式变量变形 ,例如 ?x 变成 (? x) ,使处理更方便:
假设模式是: (job ?x ?y) 实际上在系统里被表示为 (job (? x) (? y))
现在检查一个表达式是否是模式变量,只需要去校验 car 是否是 '?,而不需要从解析变量名字
因此这可以大大提高查询处理的效率
(define (query-syntax-process exp) (map-over-symbols expand-question-mark exp)) (define (map-over-symbols proc exp) (cond ((pair? exp) (cons (map-over-symbols proc (car exp)) (map-over-symbols proc (cdr exp)))) ((symbol? exp) (proc exp)) (else exp))) (define (expand-question-mark symbol) (let ((chars (symbol->string symbol))) ; 取得 symbol 的名字字符串 (if (string=? (substring chars 0 1) "?") ; 名字的第一个字符是否 '? (list '? (string->symbol (substring chars 1 (string-length chars)))) ; 取得 symbol 的名字除去 '? 后的字符串 symbol)))
经过前面变换:
- 模式变量就是以 ? 为类型 (car )的表
- 常量符号就是 Scheme 里的 一般符号
(define (var? exp) (tagged-list? exp '?)) (define (constant-symbol? exp) (symbol? exp))
为完成规则中的 模式变量换名 ,需要下面几个过程:
(define rule-counter 0) (define (new-rule-application-id) (set! rule-counter (+ 1 rule-counter)) rule-counter) (define (make-new-variable var rule-application-id) (cons '? (cons rule-application-id (cdr var))))
换名后各模式变量用的形式是 (? 3 x) , (? 8 y)
驱动循环打印结果前要把 结果中未约束的变量变换回原来形式 ,由于可能 出现规则换名中生成的模式变量 ,因此需要分别处理:
(define (contract-question-mark variable) (string->symbol (string-append "?" (if (number? (cadr variable)) ; 换名变量的特点是表里的第二个元素是数 (string-append (symbol->string (caddr variable)) "-" (number->string (cadr variable))) (symbol->string (cadr variable))))))
换名后的变量生成的变量名加了后缀
框架和约束
框架就是以一组 约束为元素的表 , 约束 用 cons 序对 表示:
(define (make-binding variable value) (cons variable value)) (define (binding-variable binding) (car binding)) (define (binding-value binding) (cdr binding)) (define (binding-in-frame variable frame) (assoc variable frame)) (define (extend variable value frame) (cons (make-binding variable value) frame))
总结
逻辑程序设计语言的基本想法:
- 在逻辑的层次上描述要求计算什么
- 由语言解释器实现一个计算过程,把需要的东西算出来
一个“做什么”的描述可能蕴涵着许多“怎样做”的过程 它可能描述了多种不同方向的计算,也可能得到许多结果(非确定性)
这里研究的逻辑编程语言是一种 查询语言 ,用于 建立 和 查询 断言数据库:
- 断言 描述 基本事实
- 规则 描述 事实之间的抽象关系
- 提供了一些 组织查询的机制 ( and , or , not 等)
逻辑程序设计的作为数学的逻辑之间的关系: 两者有相似之处,但并不等价