功能
作为一款开源的 Service Mesh 产品,Istio 提供了 流量控制 、 安全 、 监控 等方面能力
它为微服务应用提供了一个较为完整的服务治理解决方案,并且可以以统一的方式去管理和监测微服务 这些能力几乎都是对业务代码透明的,不需要修改或者只需要少量修改就能实现 接下来会对 Istio 的三大方面的功能做详细介绍
流量控制
微服务应用最大的痛点就是处理服务间的通信,而这一问题的核心其实就是流量管理
首先来看看传统的微服务应用在没有 Service Mesh 介入的情况下,是如何完成诸如金丝雀发布这样的路由功能的
假设不借助任何现成的第三方框架,一个最简单的实现方法,就是在服务间添加一个负载均衡(比如 Nginx)做代理,通过修改配置的权重来分配流量
这种方式使得对流量的管理和基础设施绑定在了一起,难以维护
而使用 Istio 就可以轻松的实现各种维度的流量控制。下图是典型的金丝雀发布策略:根据权重把 5% 的流量路由给新版本,如果服务正常,再逐渐转移更多的流量到新版本

Istio 中的流量控制功能主要分为三个方面:
- 请求路由和流量转移
- 弹性功能,包括熔断、超时、重试
- 调试能力,包括故障注入和流量镜像
路由和流量转移
Istio 为了控制服务请求,引入了 服务版本 (version)的概念,可以通过版本这一标签将服务进行区分:
- 版本的设置是非常灵活的:
- 可以根据服务的迭代编号进行定义(如 v1、v2 版本)
- 也可以根据部署环境进行定义(比如 dev、staging、production)
- 或者是自定义的任何用于区分服务的某种标记
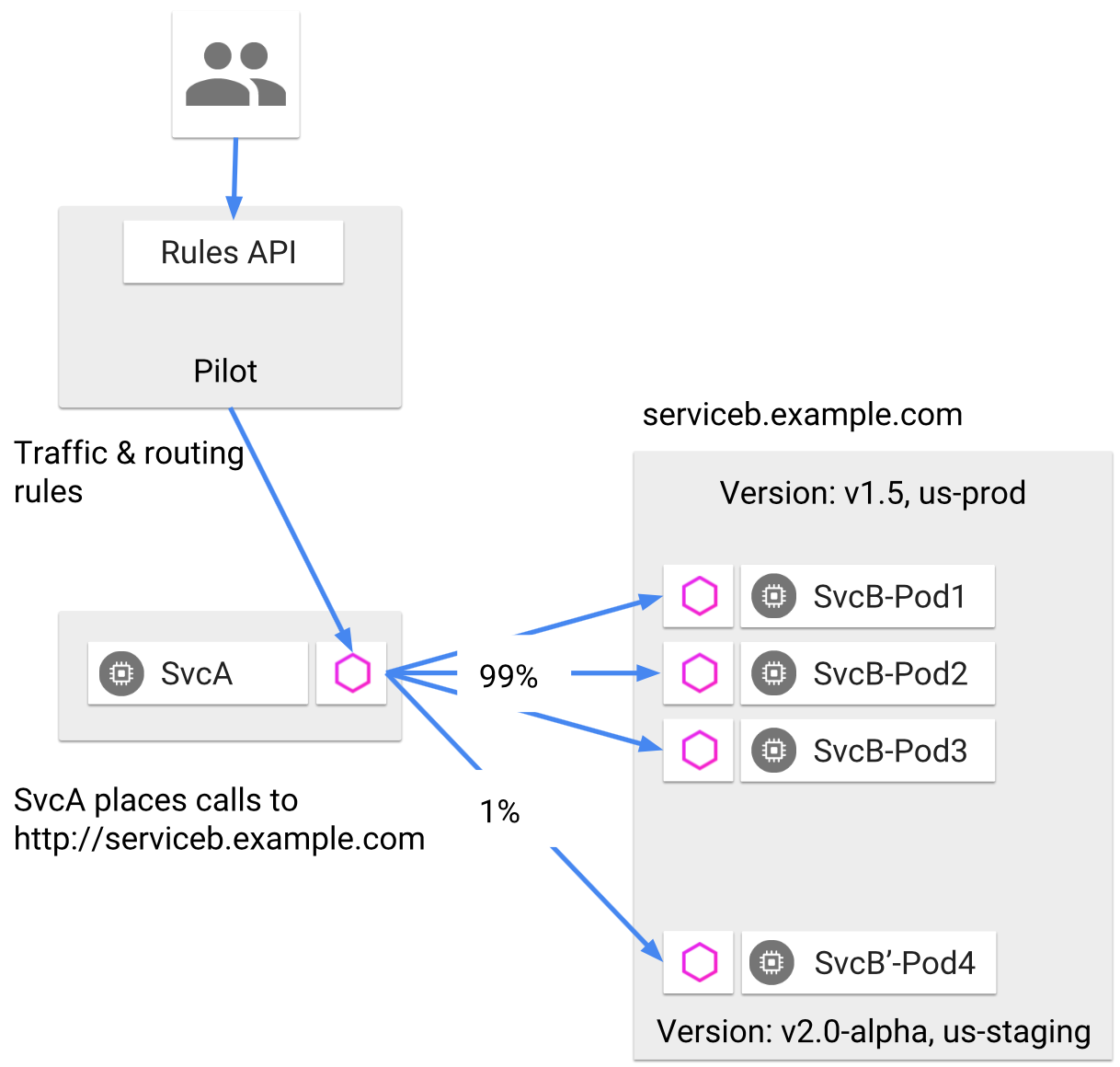
通过版本标签,Istio 就可以定义灵活的路由规则来控制流量,上面提到的金丝雀发布这类应用场景就很容易实现了。下图展示了使用服务版本实现路由分配的例子:
服务版本定义了版本号(v1.5、v2.0-alpha)和环境(us-prod、us-staging)两种信息
服务 B 包含了 4 个 Pod,其中 3 个是部署在生产环境的 v1.5 版本,而 Pod4 是部署在预生产环境的 v2.0-alpha 版本
运维人员可以根据服务版本来指定路由规则,使 99% 的流量流向 v1.5 版本,而 1% 的流量进入 v2.0-alpha 版本
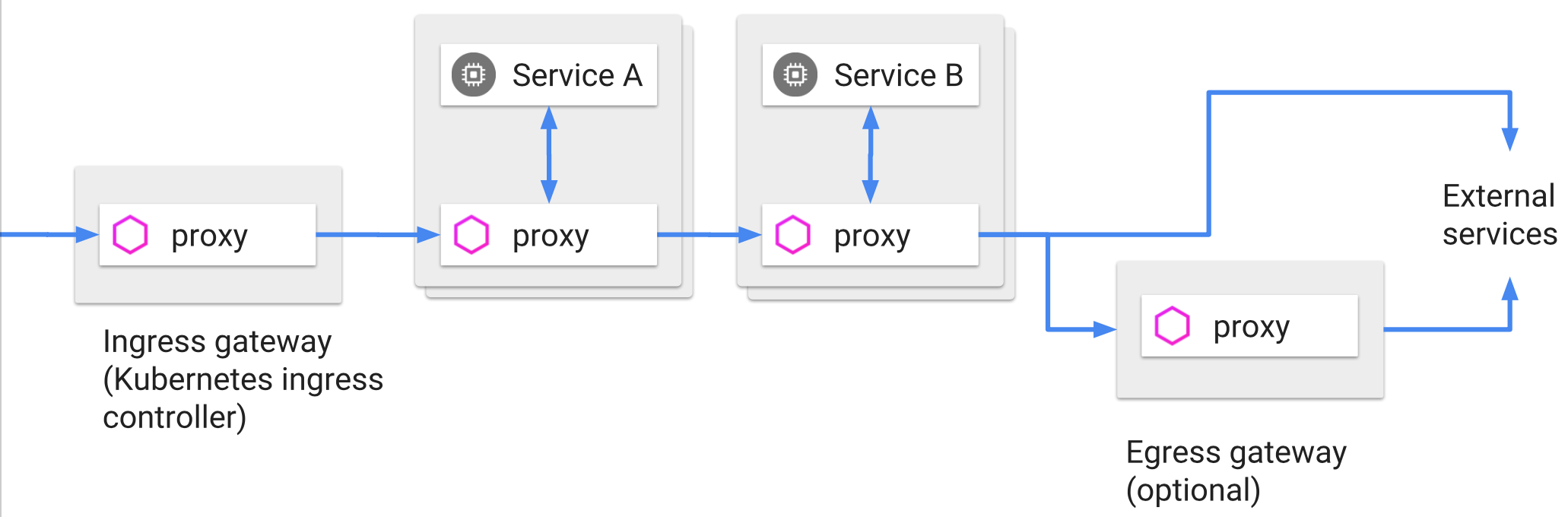
除了上面介绍的服务间流量控制外,还能控制与网格边界交互的流量。可以在系统的入口和出口处部署 Sidecar 代理,让所有流入和流出的流量都由代理进行转发。负责入和出的代理就叫做 入口网关 和 出口网关 ,它们把守着进入和流出网格的流量。下图展示了 Ingress 和 Egress 在请求流中的位置,有了他们俩,也就可以控制出入网格的流量了:
Istio 还能设置 流量策略 。比如可以对连接池相关的属性进行设置,通过修改最大连接等参数,实现对请求负载的控制。还可以对负载均衡策略进行设置,在轮询、随机、最少访问等方式之间进行切换。还能设置异常探测策略,将满足异常条件的实例从负载均衡池中摘除,以保证服务的稳定性
弹性功能
除了最核心的路由和流量转移功能外,Istio 还提供了一定的弹性功能,目前支持 超时 、 重试 和 熔断 :
- 超时就是设置一个等待时间,当上游服务的响应时间超过这个时间上限,就不再等待直接返回,就是所谓的快速失败。超时主要的目的是控制故障的范围,避免故障进行扩散
- 重试一般是用来解决网络抖动时通信失败的问题。因为网络的原因,或者上游服务临时出现问题时,可以通过重试来提高系统的可用性
在 Istio 里添加超时和重试都非常简单,只需要在路由配置里添加 timeout 和 retry 这两个关键字就可以实现
- 另外一个重要的弹性功能是熔断,它是一种非常有用的过载保护手段,可以避免服务的级联失败。熔断一共有三个状态:
- 当上游服务可以返回正常时,熔断开关处于关闭状态
- 一旦失败的请求数超过了失败计数器设定的上限,就切换到打开状态,让服务快速失败
- 熔断还有一个半开状态,通过一个超时时钟,在一定时间后切换到半开状态,让请求尝试去访问上游服务,看看服务是否已经恢复正常
- 如果服务恢复就关闭熔断,否则再次切换为打开状态
Istio 里面的熔断需要在自定义资源 DestinationRule 的 TrafficPolicy 里进行设置
调试能力
Istio 还提供了对流量进行调试的能力,包括 故障注入 和 流量镜像
对流量进行调试可以让系统具有更好的容错能力,也方便在问题排查时通过调试来快速定位原因所在
故障注入
简单来说,故障注入就是在系统中人为的设置一些故障,来测试系统的稳定性和系统恢复的能力
比如给某个服务注入一个延迟,使其长时间无响应,然后检测调用方是否能处理这种超时而自身不受影响(比如及时的终止对故障发生方的调用,避免自己被拖慢、或让故障扩展)
Isito 支持注入两种类型的故障:
- 延迟:模拟网络延迟或服务过载的情况
- 中断:模拟上游服务崩溃的情况,以 HTTP 的错误码和 TCP 连接失败来表现
Istio 里实现故障注入很方便,在路由配置中添加fault关键字即可
流量镜像
流量镜像又叫影子流量,就是通过复制一份请求并把它发送到镜像服务,从而实现流量的复制功能。流量镜像的主要应用场景有以下几种:
- 最主要的就是进行线上问题排查。一般情况下,因为系统环境,特别是数据环境、用户使用习惯等问题,很难在开发环境中模拟出真实的生产环境中出现的棘手问题,同时生产环境也不能记录太过详细的日志,因此很难定位到问题。有了流量镜像,我们就可以把真实的请求发送到镜像服务,再打开 debug 日志来查看详细的信息
- 可以通过它来观察生产环境的请求处理能力,比如在镜像服务进行压力测试
- 可以将复制的请求信息用于数据分析
流量镜像在 Istio 里实现起来也非常简单,只需要在路由配置中通添加mirror关键字即可
实现流量控制的自定义资源
Istio 里用于实现流量控制的 CRD 主要有以下几个:
- VirtualService:用于网格内路由的设置
- DestinationRule:定义路由的目标服务和流量策略
- ServiceEntry:注册外部服务到网格内,并对其流量进行管理
- Ingress、Egress gateway:控制进出网格的流量
- Sidecar:对 Sidecar 代理进行整体设置
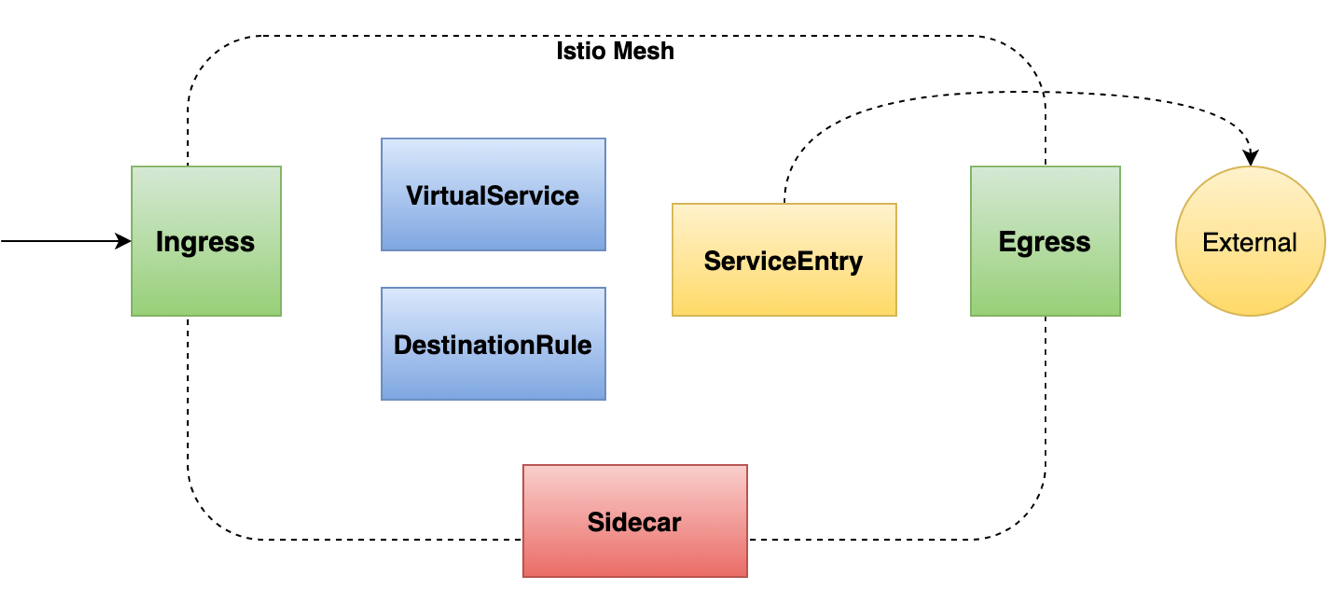
Istio 通过这些自定义资源,实现了对网格内部、网格外部、进出网格边界的流量的全面的控制。也就是说所有和网格产生交互的流量都可以被 Istio 所控制,其设计思路堪称完美
总结
- 流量控制是 Service Mesh 最核心的功能,也是服务治理最主要的手段之一
- Istio 从路由、弹性和调试三个方面提供了丰富的流量控制功能,可以对微服务应用进行全面的流量治理
- 用于实现流量控制的自定义资源主要包括:
- VirtualService
- DestinationRule
- ServiceEntry 等
安全
安全对于微服务这样的分布式系统来说至关重要,因为与单体应用在进程内进行通信不同,网络成为了服务间通信的纽带,这使得它对安全有了更迫切的需求
比如为了抵御外来攻击需要:
对流量进行加密
为保证服务间通信的可靠性,需要使用 mTLS 的方式进行交互
为控制不同身份的访问,需要设置不同粒度的授权策略
作为一个服务网格,Istio 提供了一整套完整的安全解决方案,它可以以透明的方式,为微服务应用添加安全策略
Istio 中的安全架构是由多个组件协同完成的:
- Citadel :负责安全的主要组件,用于密钥和证书的管理
- Pilot :会将安全策略配置分发给 Envoy 代理
Envoy :执行安全策略来实现访问控制
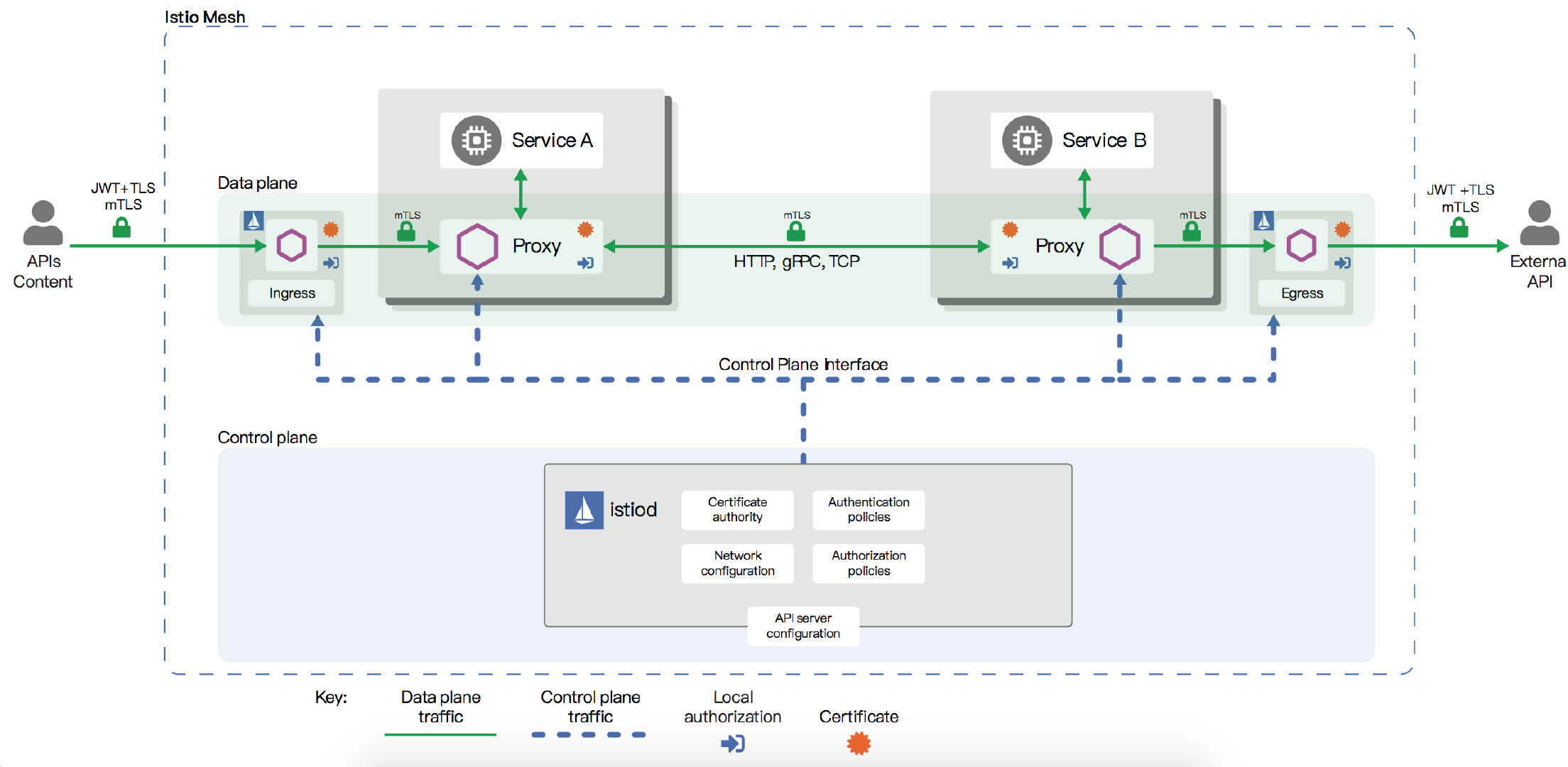
Istio 提供的安全功能主要分为 认证 和 授权 两部分
认证
Istio 提供两种类型的认证:
- 对等认证(Peer authentication):用于服务到服务的认证
- 这种方式是通过双向 TLS(mTLS)来实现的,即客户端和服务端都要验证彼此的合法性
- Istio 中提供了内置的密钥和证书管理机制,可以自动进行密钥和证书的生成、分发和轮换,而无需修改业务代码
- 请求认证(Request authentication):也叫最终用户认证,验证终端用户或客户端
- Istio 使用目前业界流行的 JWT(JSON Web Token)作为实现方案
Istio 的 mTLS 提供了一种宽容模式(permissive mode)的配置方法,使得服务可以同时支持纯文本和 mTLS 流量 用户可以先用非加密的流量确保服务间的连通性,然后再逐渐迁移到 mTLS,这种方式极大的降低了迁移和调试的成本
Istio 还提供了多种粒度的认证策略,可以支持 网格 级别、 命名空间 级别和 工作负载 级别的认证,用户可以灵活的配置各种级别的策略和组合
授权
- Istio 的授权策略可以为网格中的服务提供不同级别的访问控制,比如网格级别、命名空间级别和工作负载级别
- 授权策略支持 ALLOW 和 DENY 动作
- 每个 Envoy 代理都运行一个授权引擎
- 当请求到达代理时,授权引擎根据当前策略评估请求的上下文,并返回授权结果 ALLOW 或 DENY
- 授权功能没有显示的开关进行配置,默认就是启动状态,只需要将配置好的授权策略应用到对应的工作负载就可以进行访问控制了
Istio 中的授权策略通过自定义资源AuthorizationPolicy来配置。除了定义策略指定的目标(网格、命名空间、工作负载)和动作(容许、拒绝)外 Istio 还提供了丰富的策略匹配规则,比如可以设置来源、目标、路径、请求头、方法等条件,甚至还支持自定义匹配条件,其灵活性可以极大的满足用户需求
可观察性
面对复杂的应用环境和不断扩展的业务需求,即使再完备的测试也难以覆盖所有场景,无法保证服务不会出现故障
正因为如此,才需要“可观察性”来对服务的运行时状态进行监控、上报、分析,以提高服务可靠性
具有可观察性的系统,可以在服务出现故障时大大降低问题定位的难度,甚至可以在出现问题之前及时发现问题以降低风险。具体来说,可观察性可以:
- 及时反馈异常或者风险使得开发人员可以及时关注、修复和解决问题(告警)
- 出现问题时,能够帮助快速定位问题根源并解决问题,以减少服务损失(减损)
- 收集并分析数据,以帮助开发人员不断调整和改善服务(持续优化)
而在微服务治理之中,随着服务数量大大增加,服务拓扑不断复杂化,可观察性更是至关重要 Istio 自然也不可能缺少对可观察性的支持,它会为所有的服务间通信生成详细的遥测数据,使得网格中每个服务请求都可以被观察和跟踪 开发人员可以凭此定位故障,维护和优化相关服务,而且这一特性的引入无需侵入被观察的服务
Istio 一共提供了三种不同类型的数据从不同的角度支撑起其可观察性
指标
指标本质上是时间序列上的一系列具有特定名称的计数器的组合,不同计数器用于表征系统中的不同状态并将之数值化。通过数据聚合之后,指标可以用于查看一段时间范围内系统状态的变化情况甚至预测未来一段时间系统的行为
举一个简单的例子,系统可以使用一个计数器来对所有请求进行计数,并且周期性(周期越短,实时性越好,开销越大)的将该数值输出到时间序列数据库(比如 Prometheus)中
由此得到的一组数值通过数学处理之后,可以直观的展示系统中单位时间内的请求数及其变化趋势,可以用于实时监控系统中流量大小并预测未来流量趋势
而具体到 Istio 中,它基于四类不同的监控标识(响应延迟、流量大小、错误数量、饱和度)生成了一系列观测不同服务的监控指标,用于记录和展示网格中服务状态
除此以外,它还提供了一组默认的基于上述指标的网格监控仪表板,对指标数据进行聚合和可视化
借助指标,开发人员可以快速的了解当前网格中流量大小、是否频繁的出现异常响应、性能是否符合预期等等关键状态
但是,如前所述,指标本质上是计数器的组合和系统状态的数值化表示,所以往往缺失细节内容,它是从一个相对宏观的角度来展现整个网格或者系统状态随时间发生的变化及趋势
日志
日志是软件系统中记录软件执行状态及内部事件最为常用也最为有效的工具。而在可观测性的语境之下,日志是具有相对固定结构的一段文本或者二进制数据(区别于运行时日志),并且和系统中需要关注的事件一一对应:
- 当系统中发生一个新的事件,指标只会有几个相关的计数器自增,而日志则会记录下该事件具体的上下文。因此,日志包含了系统状态更多的细节部分。在分布式系统中,日志是定位复杂问题的关键手段
- 由于每个事件都会产生一条对应的日志,所以日志也往往被用于计费系统,作为数据源。其相对固定的结构,也提供了日志解析和快速搜索的可能,对接 ELK 等日志分析系统后,可以快速的筛选出具有特定特征的日志以分析系统中某些特定的或者需要关注的事件
在 Istio 网格中,当请求流入到网格中任何一个服务时,Istio 都会生成该请求的完整记录,包括请求源和请求目标以及请求本身的元数据等等
日志使网格开发人员可以在单个服务实例级别观察和审计流经该实例的所有流量
分布式追踪
尽管日志记录了各个事件的细节,可在分布式系统中,日志仍旧存在不足之处。日志记录的事件是孤立的,但是在实际的分布式系统中,不同组件中发生的事件往往存在因果关系
举例来说,组件 A 接收外部请求之后,会调用组件 B,而组件 B 会继续调用组件 C
在组件 A B C 中,分别有一个事件发生并各产生一条日志,但是三条日志没有将三个事件的因果关系记录下来
分布式追踪正是为了解决该问题而存在
分布式追踪通过额外数据(Span ID等特殊标记)记录不同组件中事件之间的关联,并由外部数据分析系统重新构造出事件的完整事件链路以及因果关系
在服务网格的一次请求之中,Istio 会为途径的所有服务生成分布式追踪数据并上报,通过 Zipkin 等追踪系统重构服务调用链,开发人员可以借此了解网格内服务的依赖和调用流程,构建整个网格的服务拓扑
在未发生故障时,可以借此分析网格性能瓶颈或热点服务,而在发生故障时,则可以通过分布式追踪快速定位故障点