KVM 入门
Table of Contents
简介
KVM Kernel-based Virtual Machine , 是基于 虚拟化扩展 ( Intel VT / AMD-V ) 的 X86 硬件,是 Linux 完全原生的全虚拟化解决方案
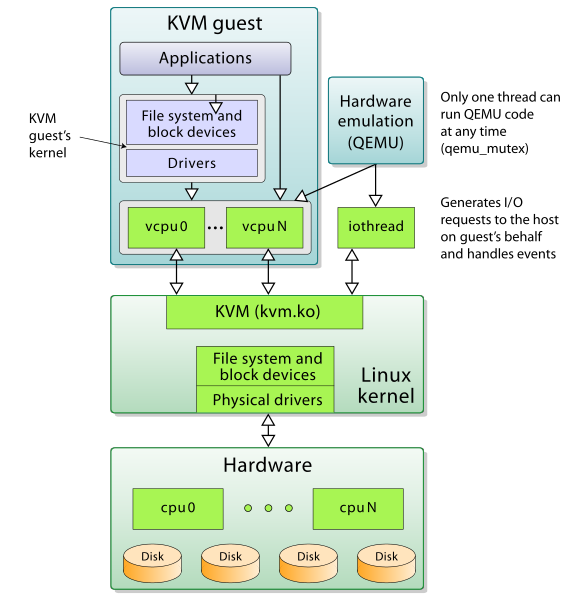
KVM 本身不执行任何模拟,需要用户空间应用程序 QEMU 通过 /dev/kvm 接口 设置 一个 客户机虚拟服务器的地址空间 ,向它 提供 模拟的 I/O,KVM 模块实现处理器的虚拟化和内存虚拟化
在硬件虚拟化技术的支持下,内核的 KVM 模块与 QEMU 的设备模拟协同工作,构成一套和物理计算机系统完全一致的虚拟化计算机软硬件系统
基础功能
CPU
在 QEMU/KVM 中,QEMU 提供对 CPU 的模拟,展现给客户机一定的 CPU 数目和 CPU 的特性。在 KVM 打开的情况下,客户机中 CPU 指令的执行由硬件处理器的虚拟化功能 (如 Intel VT-x 和 AMD AMD-V) 辅助执行,具有非常高的执行效率
在 KVM 环境中,每个客户机都是一个标准的 Linux 进程(QEMU 进程),而每一个 vCPU 在宿主机中是 QEMU 进程派生的一个普通线程
在 Linux 中,一般进程有两种执行模式:内核模式和用户模式
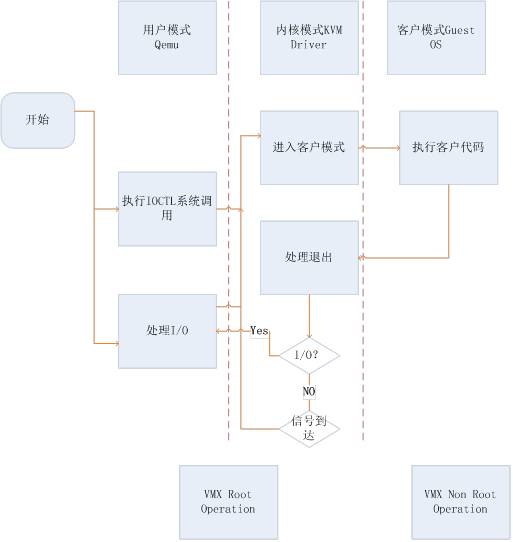
而在 KVM 环境中,增加了第三条模式: 客户模式 。vCPU 在三种执行模式下的分工如下:
- 用户模式:主要处理 I/O 的模拟和管理,由 QEMU 的代码实现
内核模式:主要处理特别需要高性能和安全相关的指令
如处理客户模式到内核模式的转换 处理客户模式下的 I/O 指令或其它特权指令引起的 VM-Exit 处理影子内存管理 (shadow MMU)
客户模式:主要执行 Guest 中的大部分指令
I/O 和一些特权指令除外,它们会引起 VM-Exit,被 hypervisor 截获并模拟
内存
内存是一个非常重要的部件,它是与 CPU 沟通的一个桥梁
在通过 QEMU 命令行启动客户机时设置内存的参数是 -m :
-m megs # 设置客户机的内存为 megs MB 大小
EPT 和 VPID
EPT Extended Page Tables 扩展页表 ,属于 Intel 的第二代硬件虚拟化技术,它是针对内存管理单元 MMU 的 虚拟化扩展
如果只是一台物理服务器,这个物理地址就只为一个操作系统服务,但如果进行了虚拟化部署,有多个虚拟机时,就存在着稳定性的隐患 因为在进行 VM Entry(虚拟机进入)与 VM Exit(虚拟机退出)时(尤其是后者),都要对内存页进行修改 但物理内存是多个虚拟机共享的,因此不能让虚拟机直接访问物理地址,否则一个虚拟机出现内存错误,就会殃及整个物理服务器的运行
所以必须要采取虚拟地址,而 EPT 的作用就在于 加速 从 虚拟机地址 至 主机物理地址 的转换过程,节省传统软件处理方式的系统开销
VPID Virtual-Processor Identifiers 虚拟处理器标识 。是对现在的 CPUID 功能的一个强化
因为在每个 CPU 中都有一个 TLB,用来缓存逻辑地址到物理地址的转换表,而每个虚拟机都有自己的虚拟 CPU 来对应
所以,在进行迁移时要进行 TLB 的转存和清除。而 VPID 则会 跟踪 每个 虚拟 CPU 的 TLB ,当进行虚拟机迁移或 VM Entry 与 VM Exit 时,VMM可以 动态的分配 非零虚拟处理器的 ID 来迅速匹配(0 ID 给 VMM 自己使用),从而避免了 TLB 的转存与清除的操作,节省了系统开销,并提高了迁移速度,同时也降低对系统性能的影响
# grep -E 'ept|vpid' /proc/cpuinfo # 查看 cpu 是否支持相应特性 # cat /sys/module/kvm_intel/parameters/{ept,vpid} # 确认是否开启 ept 和 vpid Y Y
存储
QEMU 提供了对多种块存储设备的模拟,包括 IDE , SCSI , 软盘 , U盘 , virtio 磁盘 等。qemu-kvm 提供 -drive 参数来详细定义一个存储驱动器:
-drive option[,option[,option[,...]]]
Define a new drive. Valid options are:
file=file # 指定硬盘镜像,file=镜像文件名
if=interface # 指定驱动器使用的接口类型,如 ide, scsi, sd, mtd, floppy, pflash, virtio
snapshot=snapshot # 是否启动快照
snapshot is "on" or "off" and allows to enable snapshot for given drive.
Write to temporary files instead of disk image files. In this case, the
raw disk image you use is not written back. You can however force the
write back by pressing C-a s.
cache=cache # 设置宿主机对块设备数据访问中的 cache 情况
cache is "none", "writeback", "unsafe", or "writethrough" and
controls how the host cache is used to access block data.
format=format # 指定使用的磁盘格式
Specify which disk format will be used rather than detecting the format.
Can be used to specifiy format=raw to avoid interpreting an untrusted format
header.
... ...
cache 不同模式工作原理图:
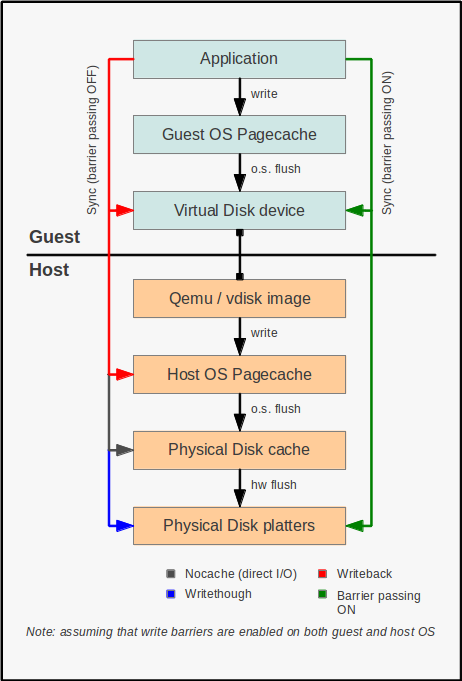
writethrough 即 直写 模式,在调用 write 写入数据的同时将数据写入 磁盘缓存 和 后端块设备 才返回,缺点是 写入性能较低 ,但是 安全性高
qcow2 格式在使用 writethrough 时性能很差 KVM cache 默认使用 writethrough
writeback 即 回写 模式,在调用 write 写入数据时只将数据写入到 主机页缓存 中即返回,写入性能高,有安全风险
当使用 -snapshot 选项的时候, writeback cache 是默认项
- none 关闭缓存 ,直接从磁盘 IO 读写
- unsafe 这个选项告诉 QEMU 不需要写入任何数据到磁盘,只要保证在缓存即可
qemu-img
qemu-img 是 QEMU 的 磁盘管理工具 ,支持多种虚拟镜像格式
$ qemu-img -h | grep Supported Supported formats: raw cow qcow vdi vmdk cloop dmg bochs vpc vvfat qcow2 qed parallels nbd blkdebug host_cdrom host_floppy host_device file
qemu-img 默认创建的格式是 raw ,man 手册中对几种格式也都有介绍 以下为对 raw 和 qcow2 镜像的详细介绍
raw
原始的磁盘镜像格式,qemu-img 默认支持的格式
它的优势在于它非常简单而且非常容易移植到其他模拟器(emulator,QEMU 也是一个 emulator)上去使用 如果客户机文件系统(如 Linux 上的 ext2/ext3/ext4、Windows 的 NTFS)支持"空洞" (hole),那么镜像文件只有在被写有数据的扇区才会真正占用磁盘空间,从而有节省磁盘空间的作用 qemu-img 默认的 raw 格式的文件其实是稀疏文件(sparse file)「稀疏文件就是在文件中留有很多空余空间,留备将来插入数据使用 如果这些空余空间被 ASCII 码的 NULL 字符占据,并且这些空间相当大,那么这个文件就被称为稀疏文件,而且,并不分配相应的磁盘块」 dd 命令创建的也是 raw 格式,不过 dd 一开始就让镜像实际占用了分配的空间,而没有使用稀疏文件的方式对待空洞而节省磁盘空间 尽管一开始就实际占用磁盘空间的方式没有节省磁盘的效果,不过它在写入新的数据时不需要宿主机从现有磁盘空间中分配,从而在第一次写入数据时性能会比稀疏文件的方式更好一点
简单来说,raw 有以下几个特点:
- 寻址简单,访问效率高
可以通过格式转换工具方便地转换为其它格式
格式实现简单,不支持压缩、快照和加密
- 能够直接被宿主机挂载,不用开虚拟机即可在宿主和虚拟机间进行数据传输
qcow2
qcow2 是 qcow 的一种改进,是 QEMU 实现的一种虚拟机镜像格式。 更小的虚拟硬盘空间 (尤其是宿主分区不支持 hole 的情况下),支持 压缩 加密 , 快照 功能, 磁盘读写性能较 raw 差
qemu-img 支持的命令
check
qemu-img check [-f fmt] filename
参数 -f fmt 是指定文件的格式,如果不指定格式 qemu-img 会自动检测
filename 是磁盘镜像文件的名称(包括路径)
对磁盘镜像文件进行一致性检查,查找镜像文件中的错误,目前仅支持对 qcow2 , qed , vdi 格式文件的检查。其中:
- qcow2 是 QEMU 0.8.3 版本引入的镜像文件格式,也是目前使用最广泛的格式
- qed (QEMU enhanced disk)是从 QEMU 0.14 版开始加入的增强磁盘文件格式,为了避免 qcow2 格式的一些缺点,也为了提高性能,不过目前还不够成熟
- vdi (Virtual Disk Image)是 Oracle 的 VirtualBox 虚拟机中的存储格式
$ qemu-img check CentOS6.4-x86_64.qcow2 No errors were found on the image.
create
qemu-img create [-f fmt] filename [size]
创建一个格式为 fmt 大小为 size 文件名为 filename 的镜像文件:
$ qemu-img create -f qcow2 test.qcow2 10G Formatting 'test.qcow2', fmt=qcow2 size=10737418240 encryption=off cluster_size=65536 $ qemu-img create -f qcow2 test.raw 10G Formatting 'test.raw', fmt=qcow2 size=10737418240 encryption=off cluster_size=65536
注意 :这里的 qcow2 后缀只是为了便于自己区分格式方便 如果不加后缀也可以通过 qemu-img 来获取镜像的格式
info
qemu-img info [-f fmt] filename
显示 filename 镜像文件的信息:
- 如果文件是使用稀疏文件的存储方式,也会显示出它的本来分配的大小以及实际已占用的磁盘空间大小
- 如果文件中存放有客户机快照,快照的信息也会被显示出来
$ qemu-img info test.qcow2 image: test.qcow2 file format: qcow2 virtual size: 10G (10737418240 bytes) disk size: 136K cluster_size: 65536 $ qemu-img info test.raw # qemu-img 生成 raw 格式镜像也是采用稀疏文件方式存储的 image: test.raw file format: qcow2 virtual size: 10G (10737418240 bytes) disk size: 136K cluster_size: 65536 $ dd </dev/zero >test.dd bs=1MB count=1000 1000+0 records in 1000+0 records out 1000000000 bytes (1.0 GB) copied, 1.80597 s, 554 MB/s $ qemu-img info test.dd # 可以看到 dd 产生的格式也是 raw 格式的,并且没有用到稀疏存储方式 image: test.dd file format: raw virtual size: 954M (1000000000 bytes) disk size: 954M
convert
qemu-img convert [-c] [-f fmt] [-O output_fmt] [-o options] filename [filename2 […]] output_filename
镜像格式转换,将 fmt 格式的 filename 镜像文件根据 options 选项转换为格式为 output_fmt 的名为 output_filename 的镜像文件
它支持不同格式的镜像文件之间的转换,比如可以用 VMware 用的 vmdk 格式文件转换为 qcow2 文件 这对从其他虚拟化方案转移到 KVM 上的用户非常有用
- 一般来说,输入文件格式 fmt 由 qemu-img 工具自动检测到,而输出文件格式 output_fmt 根据自己需要来指定,默认会被转换为与 raw 文件格式(且默认使用稀疏文件的方式存储以节省存储空间)
- -c 参数是对输出的镜像文件进行压缩,不过只有 qcow2 和 qcow 格式的镜像文件才支持压缩,而且这种压缩是只读的,如果压缩的扇区被重写,则会被重写为未压缩的数据
- 同样可以使用 -o options 来指定各种选项,如:后端镜像、文件大小、是否加密等等
- 使用 backing_file 选项来指定后端镜像,让生成的文件是 copy-on-write 的增量文件,这时必须让转换命令中指定的后端镜像与输入文件的后端镜像的内容是相同的,尽管它们各自后端镜像的目录、格式可能不同
$ qemu-img info test.dd image: test.dd file format: raw virtual size: 954M (1000000000 bytes) disk size: 954M $ qemu-img convert -O qcow2 test.dd test_qcow2.qcow2 $ qemu-img info test_qcow2.qcow2 image: test_qcow2.qcow2 file format: qcow2 virtual size: 954M (1000000000 bytes) disk size: 136K cluster_size: 65536
如果使用 qcow2 、 qcow 、 cow 等作为输出文件格式来转换 raw 格式的镜像文件(非稀疏文件格式) 镜像转换还可以起到将镜像文件转化为更小的镜像,因为它可以将空的扇区删除使之在生成的输出文件中并不存在
网络
QEMU 支持的网络模式
- 基于 网桥 的虚拟网卡
- 基于 NAT 的虚拟网络
- QEMU 内置的 用户模式 网络
- 直接分配 网络设备 的网络 VT-d 和 SR-IOV
qemu-kvm 通过 -net 参数配置网络选项:
-net nic[,vlan=n][,macaddr=mac][,model=type][,name=name][,addr=addr][,vectors=v]
Create a new Network Interface Card and connect it to VLAN n (n = 0 is
the default). The NIC is an rtl8139 by default on the PC target.
Optionally, the MAC address can be changed to mac, the device address
set to addr (PCI cards only), and a name can be assigned for use in
monitor commands. Optionally, for PCI cards, you can specify the
number v of MSI-X vectors that the card should have; this option
currently only affects virtio cards; set v = 0 to disable MSI-X. If no
-net option is specified, a single NIC is created. Qemu can emulate
several different models of network card. Valid values for type are
"virtio", "i82551", "i82557b", "i82559er", "ne2k_pci", "ne2k_isa",
"pcnet", "rtl8139", "e1000", "smc91c111", "lance" and "mcf_fec". Not
all devices are supported on all targets. Use -net nic,model=? for a
list of available devices for your target.
- -net nic 必需的参数,表明是一个网卡的配置
- vlan=n 表示将网卡放入到编号为 n 的 VLAN,默认为 0
- macaddr=mac 自定义 MAC 地址
- model=type 设置模拟的网卡类型,默认为 rtl8139
如果提供 VM 多个网卡,则需要多次使用 -net 参数
桥接网络
手动桥接:qemu-kvm安装或者启动虚拟系统的时候如果需要和外界通信,那么就要设置网络桥接:
/usr/libexec/qemu-kvm -m 1024 \ -drive file=/data/images/CentOS6_4.qcow2,if=virtio \ -net nic,model=virtio -net tap,script=no -nographic -vnc :0
使用 -net tap,script=no 方式启动之后,系统会生成 tapX 的虚拟网卡,默认是 DOWN 状态:
$ ip link show dev tap0 37: tap0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN qlen 500 link/ether d2:b0:af:7b:23:0f brd ff:ff:ff:ff:ff:ff
如果想和外界通信,可以手动执行生效,先查询当前与 br0 桥接的设备,并没有 tap 相关的网卡:
$ brctl show br0 bridge name bridge id STP enabled interfaces br0 8000.b8975a626020 no eth0 vnet0 vnet1
需要把 tap0 也桥接到 br0 下以便和外界通信,方法如下:
$ ip link set tap0 up # 使 tap0 状态变为 up $ brctl addif br0 tap0 # 桥接 tap0 到 br0 $ brctl show br0 bridge name bridge id STP enabled interfaces br0 8000.b8975a626020 no eth0 tap0 vnet0 vnet1
brctl delif br0 tap0 删除桥接网络
qemu-kvm 工具在客户机关闭时会自动解除 TAP 设备的 bridge 绑定,所以这一步无需操作
脚本实现
$ /usr/libexec/qemu-kvm -m 1024 \ -drive file=/data/images/CentOS6_4.qcow2,if=virtio \ -net nic,model=virtio -net tap,script=/tmp/qemu-ifup.sh -nographic -vnc :0
tap,script=/tmp/qemu-ifup.sh 指定 script 网络配置启动前启动脚本:
# cat /tmp/qemu-ifup.sh #!/bin/bash # 桥接网络设备 switch=br0 if [ -n $1 ]; then # $1 为 qemu-kvm 传递值,这里是 tap ip link set $1 up brctl addif ${switch} $1 exit 0 else echo "no interface!" exit 1 fi
高级功能
半虚拟驱动
virtio
KVM 是必须使用硬件虚拟化辅助技术(如 Intel VT-x、AMD-V)的 hypervisor,在 CPU 运行效率方面有硬件支持,其效率是比较高的 在有 Intel EPT 特性支持的平台上,内存虚拟化的效率也较高 QEMU/KVM 提供了全虚拟化环境,可以让客户机不经过任何修改就能运行在 KVM 环境中 不过,KVM 在 I/O 虚拟化方面,传统的方式是使用 QEMU 纯软件的方式来模拟 I/O 设备(如模拟的网卡、磁盘、显卡等等),其效率并不非常高
在 KVM 中,可以在客户机中使用 半虚拟化驱动 (Paravirtualized Drivers, PV Drivers )来提高客户机的性能(特别是 I/O 性能 )。目前,KVM 中实现半虚拟化驱动的方式是采用了 virtio 这个 Linux 上的设备驱动标准框架
QEMU 模拟 I/O 设备
使用 QEMU 模拟 I/O 的情况下,当客户机中的设备驱动程序(device driver)发起 I/O 操作请求之时:
- KVM 模块中的 I/O 操作捕获代码会拦截这次 I/O 请求,然后经过处理后将本次 I/O 请求的信息存放到 I/O 共享页,并通知用户控件的 QEMU 程序
- QEMU 模拟程序获得 I/O 操作的具体信息之后,交由硬件模拟代码来模拟出本次的 I/O 操作,完成之后,将结果放回到 I/O 共享页,并通知 KVM 模块中的 I/O 操作捕获代码
- 最后,由 KVM 模块中的捕获代码读取 I/O 共享页中的操作结果,并把结果返回到客户机中
当然,这个操作过程中客户机作为一个 QEMU 进程在等待I/O时也可能被阻塞 另外,当客户机通过 DMA(Direct Memory Access)访问大块 I/O 之时,QEMU 模拟程序将不会把操作结果放到 I/O 共享页中,而是通过内存映射的方式将结果直接写到客户机的内存中去,然后通过 KVM 模块告诉客户机 DMA 操作已经完成
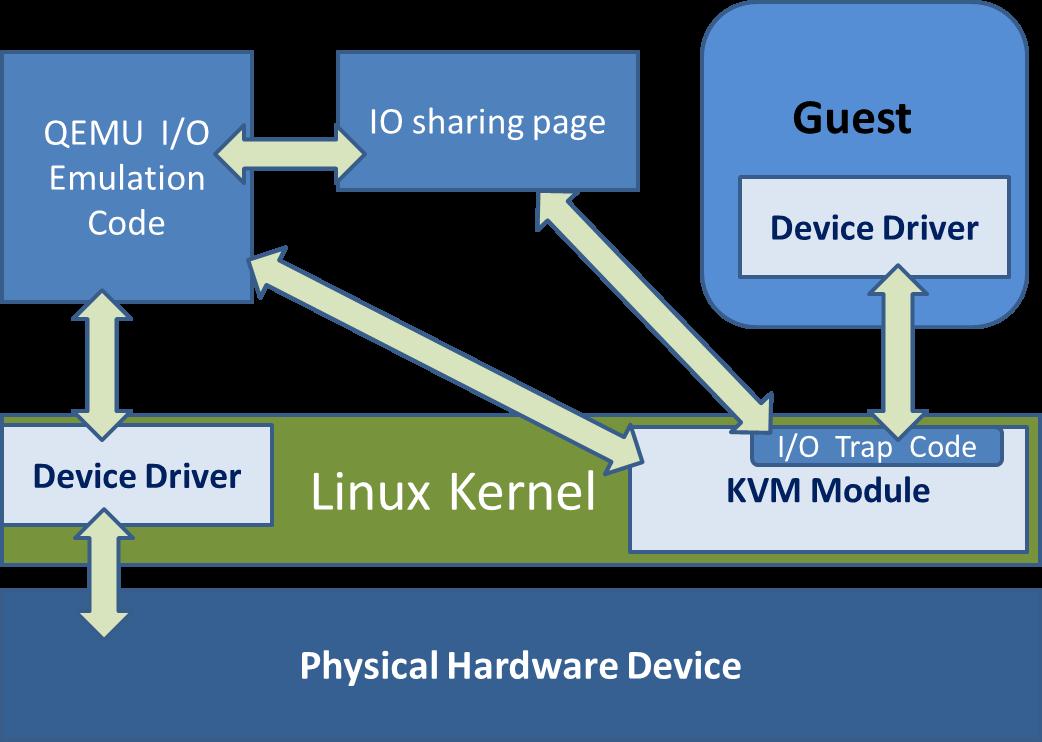
QEMU 模拟 I/O 设备的方式:
优点:可以通过软件模拟出各种各样的硬件设备,包括一些不常用的或者很老很经典的设备(如 RTL8139 网卡),而且它不用修改客户机操作系统,就可以实现模拟设备在客户机中正常工作
在 KVM 客户机中使用这种方式,对于解决手上没有足够设备的软件开发及调试有非常大的好处
- 缺点是,每次 I/O 操作的路径比较长,有较多的 VMEntry、VMExit 发生,需要多次上下文切换(context switch),也需要多次数据复制,所以它的性能较差
virtio 的基本原理和优缺点
virtio 是一个在 hypervisor 之上的 抽象 API 接口 ,让客户机知道自己运行在虚拟化环境中,从而与 hypervisor 根据 virtio 标准协作,从而在客户机中达到更好的性能(特别是 I/O 性能)。其中:
- 前端驱动(frondend,如 virtio-blk , virtio-net 等)是在 客户机 中存在的驱动程序模块
- 后端处理程序(backend)是在 QEMU 中实现的
- 在这前后端驱动之间,还定义了两层来支持客户机与 QEMU 之间的通信。其中
virtio 这一层是 虚拟队列接口 ,它在概念上将 前端驱动程序 附加 到 后端处理程序
一个前端驱动程序可以使用 0 个或多个队列,具体数量取决于需求 例如,virtio-net 网络驱动程序使用两个虚拟队列(一个用于接收,另一个用于发送),而 virtio-blk 块驱动程序仅使用一个虚拟队列 虚拟队列实际上被实现为跨越客户机操作系统和 hypervisor 的衔接点,但它可以通过任意方式实现,前提是客户机操作系统和 virtio 后端程序都遵循一定的标准,以相互匹配的方式实现它
virtio-ring 实现了 环形缓冲区 ( ring buffer ),用于 保存 前端驱动和后端处理程序 执行的信息 ,并且它可以 一次性 保存前端驱动的 多次 I/O 请求 ,并且交由后端驱动去 批量处理 ,最后实际调用 宿主机 中 设备驱动 实现物理上的 I/O 操作
这样做就可以根据约定实现批量处理而不是客户机中每次 I/O 请求都需要处理一次,从而提高客户机与 hypervisor 信息交换的效率
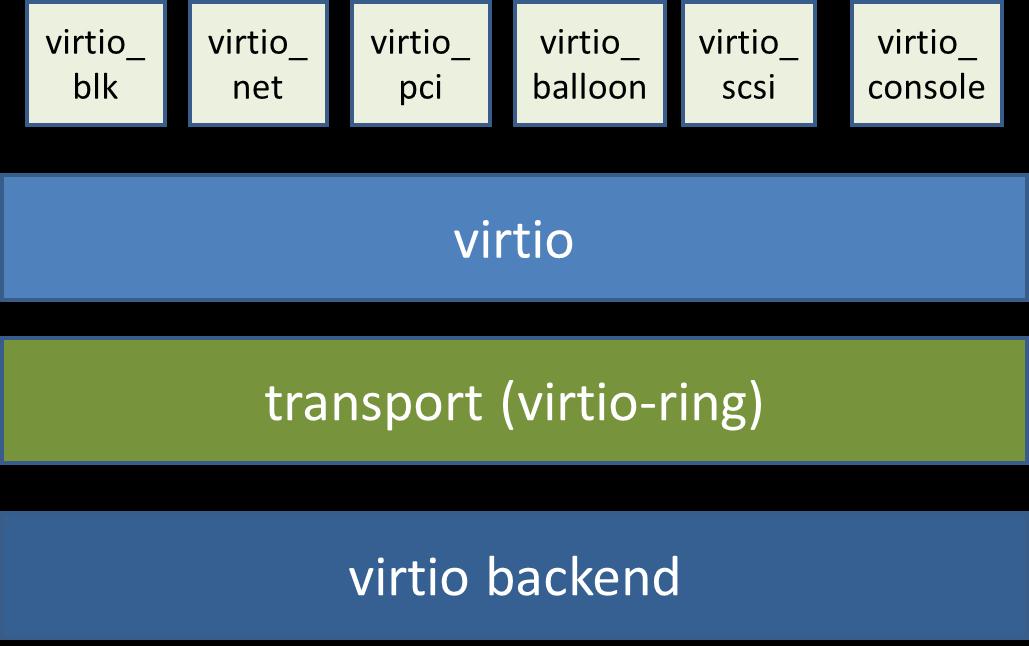
virtio 半虚拟化驱动的方式:
优点是可以获得很好的 I/O 性能,其性能几乎可以达到和 native(即:非虚拟化环境中的原生系统)差不多的 I/O 性能
所以,在使用 KVM 之时,如果宿主机内核和客户机都支持 virtio 的情况下,一般推荐使用 virtio 达到更好的性能
缺点,它必须要客户机安装特定的Virtio驱动使其知道是运行在虚拟化环境中,且按照 Virtio 的规定格式进行数据传输
不过客户机中可能有一些老的 Linux 系统不支持 virtio 和主流的Windows系统需要安装特定的驱动才支持 Virtio 较新的一些 Linux 发行版(如 RHEL 6.x、Fedora 17 等)默认都将 virtio 相关驱动编译为模块,可直接作为客户机使用 virtio Windows 系统需要额外的安装相应的 virtio 区别,virtio-win
virtio_net 和 vhost_net
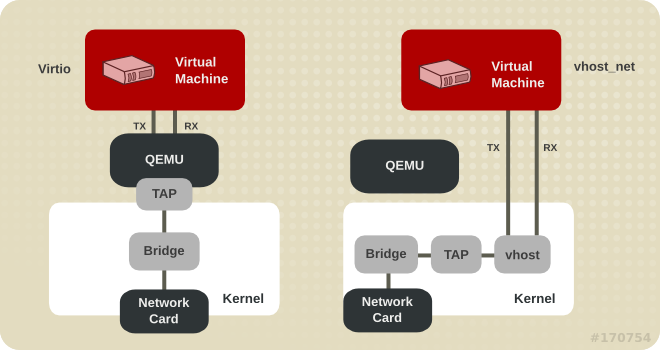
- 使用 virtio_net 半虚拟化驱动,可以提高网络吞吐量和降低网络延迟
- vhost_net 能够把网络 IO 请求的后端处理在 内核空间 完成,则效率更高,会提高网络吞吐量和减少网络延迟。
virtio_blk
virtio_blk 驱动使用 virtio API 为客户机提供了一个高效访问块设备 I/O 的方法。使用 virtio_blk 驱动的磁盘显示为 /dev/vd*
Device Assignment and SR-IOV
热插拔
热插拔可以提高服务器扩展性、灵活性以及对相关硬件问题的及时恢复能力
在服务器中,可以实现热插拔的部件主要是 SATA 硬盘、CPU、内存、USB、网卡、风扇等
在 KVM 虚拟化环境中,也支持客户机相应的设备热插拔。目前,KVM 对热插拔的支持还不是很完善,主要支持 PCI 设备和 CPU 的热插拔,内存的热插拔目前还不是很完善
动态迁移
动态迁移:也叫在线迁移。就是在保证虚拟机上服务正常运行的同时,将一个虚拟机系统从一个物理主机移动到另一个物理主机的过程
该过程不会对最终用户造成明显的影响,从而使得管理员能够在不影响用户正常使用的情况下,对物理服务器进行离线维修或者升级 与静态迁移不同的是,为了保证迁移过程中虚拟机服务的可用,迁移过程仅有非常短暂的停机时间
迁移的前面阶段,服务在源主机的虚拟机上运行,当迁移进行到一定阶段,目的主机已经具备了运行虚拟机系统的必须资源,经过一个非常短暂的切换,源主机将控制权转移到目的主机,虚拟机系统在目的主机上继续运行。对于虚拟机服务本身而言,由于切换的时间非常短暂,用户感觉不到服务的中断,因而迁移过程对用户是透明的
动态迁移适用于对虚拟机服务可用性要求很高的场合,KVM 虚拟机在物理主机之间迁移的实现
管理工具
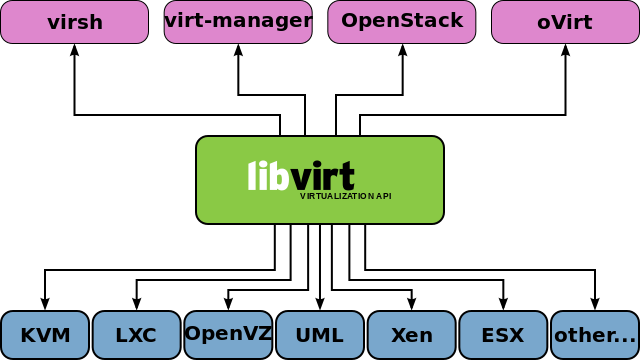
libvirt
libvirt 是目前使用最为广泛的对 KVM 虚拟机进行管理的 工具 和 应用程序接口 ( API ),而且一些常用的虚拟机管理工具(如 virsh , virt-install , virt-manager 等)和云计算框架平台(如 OpenStack , OpenNebula , Eucalyptus 等)都在底层使用 libvirt 的应用程序接口。libvirt 是为了更方便地管理平台虚拟化技术而设计的开放源代码的应用程序接口、守护进程和管理工具,它不仅提供了对虚拟化客户机的管理,也提供了对虚拟化网络和存储的管理
尽管 libvirt 项目最初是为 Xen 设计的一套API,但是目前对KVM等其他 Hypervisor 的支持也非常的好 libvirt 支持多种虚拟化方案,既支持包括 KVM、QEMU、Xen、VMware、VirtualBox 等在内的平台虚拟化方案 又支持 OpenVZ、LXC 等 Linux 容器虚拟化系统,还支持用户态 Linux(UML)的虚拟化
libvirt 作为中间适配层,让底层 Hypervisor 对上层用户空间的管理工具是可以做到完全透明的,因为 libvirt 屏蔽 了底层 各种 Hypervisor 的细节 ,为上层管理工具提供了一个统一的、较稳定的接口(API)。通过 libvirt,一些用户空间管理工具可以管理各种不同的 Hypervisor 和上面运行的客户机
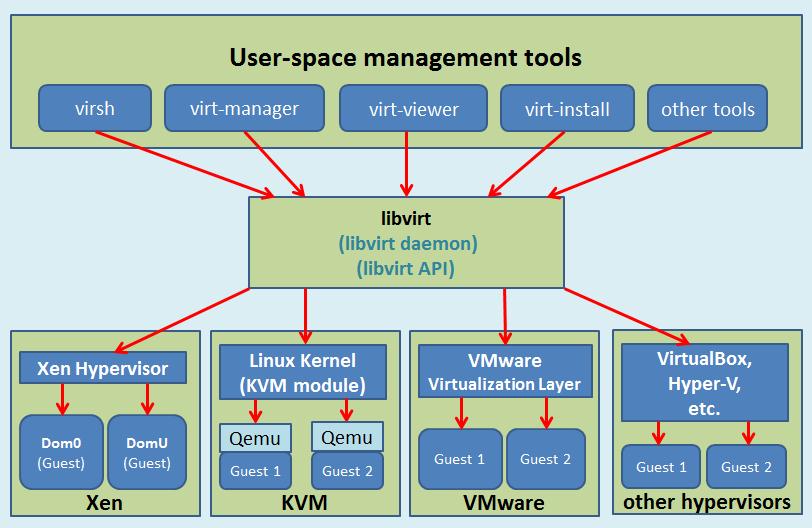
libvirt 的管理功能主要包含如下五个部分:
- 域的管理:包括
对 节点上的域 的 各个生命周期 的管理
如:启动、停止、暂停、保存、恢复和动态迁移
对 多种设备类型 的 热插拔 操作
包括:磁盘、网卡、内存和 CPU,当然不同的 Hypervisor 上对这些热插拔的支持程度有所不同
远程节点的管理:只要物理节点上运行了 libvirtd 这个守护进程, 远程的管理程序 就可以 连接 到 该节点进程管理操作 ,经过 认证 和 授权 之后,所有的 libvirt 功能都可以被访问和使用
libvirt 支持多种网络远程传输类型,如 SSH、TCP 套接字、Unix domain socket、支持 TLS 的加密传输等 假设使用最简单的 SSH,则不需要额外配置工作,比如:example.com 节点上运行了 libvirtd,而且允许 SSH 访问 在远程的某台管理机器上就可以用如下的命令行来连接到 example.com 上 virsh -c qemu+ssh://root@example.com/system ,从而管理其上的域
存储的管理:任何运行了 libvirtd 守护进程的主机,都可以通过 libvirt 来管理 不同类型的存储
如:创建不同格式的客户机镜像(qcow2、raw、qde、vmdk等)、挂载 NFS 共享存储系统、查看现有的 LVM 卷组、创建新的 LVM 卷组和逻辑卷、对磁盘设备分区、挂载 iSCSI 共享存储,等等 当然 libvirt 中,对存储的管理也是支持远程管理的
网络的管理:任何运行了 libvirtd 守护进程的主机,都可以通过libvirt来管理物理的和逻辑的 网络接口
包括:列出现有的网络接口卡,配置网络接口,创建虚拟网络接口,网络接口的桥接,VLAN 管理,NAT 网络设置,为客户机分配虚拟网络接口 ......
- 提供一个稳定、可靠、高效的应用程序接口 API 以便可以完成前面的 4 个管理功能
libvirt 主要由三个部分组成,它们分别是:
- 应用程序编程接口 API 库:为了其他虚拟机管理工具(如 virsh、virt-manager等)提供虚拟机管理的程序库支持
- 一个 守护进程 libvirtd :负责执行对节点上的域的管理工作,在用各种工具对虚拟机进行管理之时,这个守护进程一定要处于运行状态中,而且这个守护进程可以分为两种:
- 一种是 root 权限的libvirtd,其权限较大,可以做所有支持的管理工作
- 一种是普通用户权限的 libvirtd,只能做比较受限的管理工作
- 一个默认 命令行管理工具 virsh
启动物理分区的Windows系统
需求
先来说说我笔记本的硬盘配置,我通常装两块硬盘,一块安装Windows,另一块安装Linux 平常几乎只使用Linux,Window常年不开机,容易造成一块盘使用过度而另一块盘闲置的现象 且在这个微软几近垄断操作系统的时代,想要安安静静用Linux完成所有事情是不现实的 不提微软Office全家桶,哪怕是一众国产软件对Linux接近于0的支持也让无数用户直摇头
想解决这个问题,虚拟机(Virtual Machine, VM)运行Windows是一个非常好的方案。在Linux中运行Windows VM,其虚拟硬盘是文件模拟的,相当于两个系统同时损耗一块硬盘,对硬盘性能和寿命而言无疑是雪上加霜
针对这个问题,一个显而易见的解决方案是将Windows所在硬盘利用起来 但Linux对NTFS分区的支持毕竟不是原生,抛开性能不谈,不少文件系统间的特性也无法兼容,使用中总会影响体验
那如果能够利用QEMU/KVM启动物理硬盘(分区)上的Windows系统,让Windows系统作为VM直接访问硬盘,不经过Linux Host,岂不是可以均衡两块硬盘之间的利用率,减轻Linux系统盘的负担并提升性能?
同时如果利用Virtio-SCSI驱动优化硬盘,更是可以达到提升VM硬盘性能的效果!
原理
本人物理硬盘上安装的Windows系统版本是Win10
要想通过QEMU/KVM启动物理分区上的Win10,首先需要 定位 到 目标分区 ,然后需要为目标分区 创建 对应的 启动分区 。现代启动分区是 EFI分区 ,通过 Windows ISO镜像 即可创建。使用 fdisk 命令可以列出Win10所在硬盘分区布局:
$ sudo fdisk -l /dev/nvme1n1
Disk /dev/nvme1n1: 953.87 GiB, 1024209543168 bytes, 2000409264 sectors
Disk model: UMIS RPEYJ1T24MKN2QWY
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: gpt
Disk identifier: 5FDAE92B-259B-4AB8-8D55-DE3A1EE8D99E
Device Start End Sectors Size Type
/dev/nvme1n1p1 2048 34815 32768 16M Microsoft reserved
/dev/nvme1n1p2 34816 268470271 268435456 128G Microsoft basic data
/dev/nvme1n1p3 268470272 2000408575 1731938304 825.9G Microsoft basic data
其中:
- /dev/nvme1n1p2: Win10系统所在分区 C
- /dev/nvme1n1p3: Win10的扩展分区 D
直接将 /dev/nvme1n1p2 穿透到VM 作为系统盘无法启动系统 因为缺少系统启动依赖的必要元数据,而这些元数据存储在EFI分区
需要做的是用 mdadm 命令 创建 一个 线性阵列 ,将/dev/nvme1n1p2作为线性阵列中的一个分区,并使用其中另一个分区作为EFI分区引导该分区启动。根据GPT分区表规范,最终要创建的线性阵列分区布局如下:
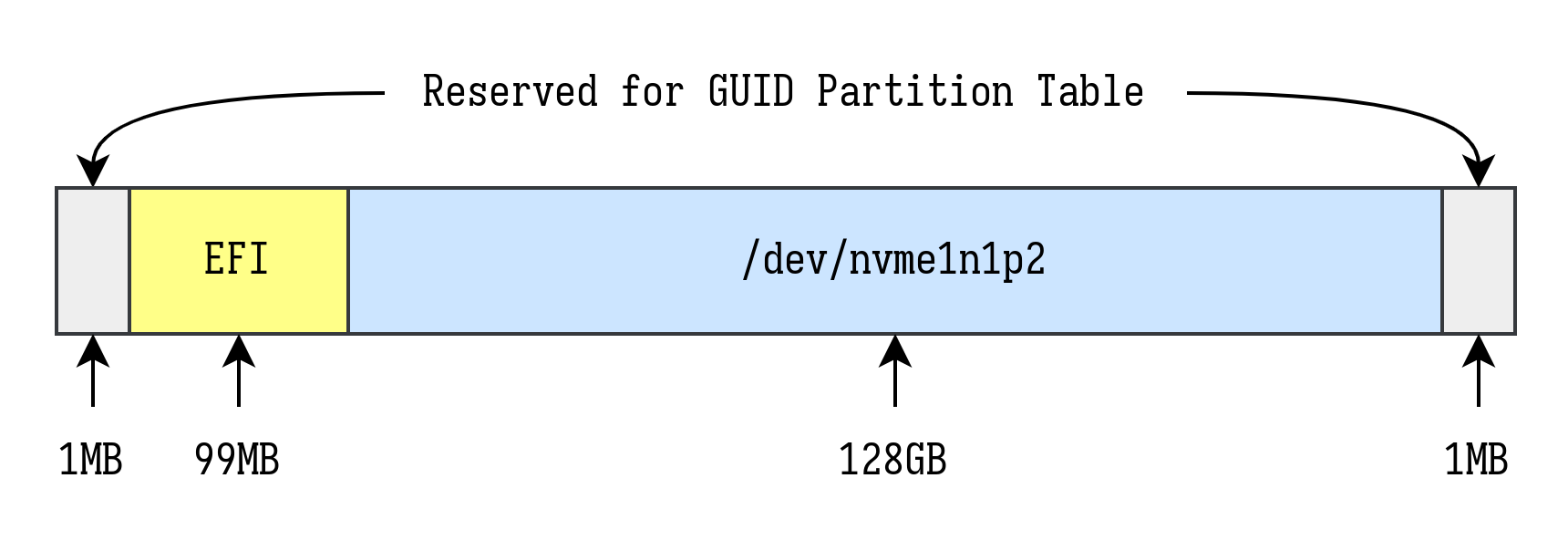
接着将配置好的线性阵列作为一个整体供应给VM,作为其启动盘即可启动物理分区中的Win10系统
步骤
创建线性阵列
首先,创建两个文件,大小分别为 100MB 和 1MB ,用于后续 挂载 为 文件Loop设备 ,作为线性阵列的一部分:
sudo mkdir -p /etc/libvirt/hooks/qemu.d/win10/md0 # 创建目标路径 cd /etc/libvirt/hooks/qemu.d/win10/md0 dd if=/dev/zero of=loop-efi0 bs=1M count=100 dd if=/dev/zero of=loop-efi1 bs=1M count=1
创建启动线性阵列脚本 start-md0.sh :
#!/usr/bin/env bash WIN_PART=/dev/nvme1n1p2 EFI_DIR="/etc/libvirt/hooks/qemu.d/win10/md0" if [[ -e /dev/md0 ]]; then echo "/dev/md0 already exists" > /dev/kmsg 2>&1 exit 1 fi if mountpoint -q -- "${WIN_PART}"; then echo "Unmounting ${WIN_PART}..." > /dev/kmsg 2>&1 umount ${WIN_PART} fi modprobe loop modprobe linear LOOP0=$(losetup -f "${EFI_DIR}/loop-efi0" --show) LOOP1=$(losetup -f "${EFI_DIR}/loop-efi1" --show) mdadm --build --verbose /dev/md0 --chunk=512 --level=linear --raid-devices=3 ${LOOP0} ${WIN_PART} ${LOOP1} chown $USER:disk /dev/md0 echo "$LOOP0 $LOOP1" > "${EFI_DIR}/.win10-loop-devices"
与之对应的停止线性阵列脚本 stop-md0.sh :
#!/usr/bin/env bash EFI_DIR="/etc/libvirt/hooks/qemu.d/win10/md0" mdadm --stop /dev/md0 xargs losetup -d < "${EFI_DIR}/.win10-loop-devices"
以sudo运行start-md0.sh脚本,此时操作系统将多出一个新的 块设备 /dev/md0 ,这就是创建的 线性阵列 。接下来为 /dev/md0 创建 GPT分区表 ,并进行分区:
sudo parted /dev/md0 (parted) unit s (parted) mktable gpt (parted) mkpart primary fat32 2048 204799 # 取决于loop-efi0文件大小 (parted) mkpart primary ntfs 204800 268640255 # 取决于Win10物理分区扇区数 (parted) set 1 boot on (parted) set 1 esp on (parted) set 2 msftdata on (parted) name 1 EFI (parted) name 2 Windows (parted) quit
注意:为Win10分区指定的结束扇区是 268435456 + 204800 - 1 = 268640255 具体数值需要根据 Win10 物理分区扇区数计算
然后为EFI分区进行格式化:
sudo mkfs.msdos -F 32 -n EFI /dev/md0p1
操作完成后, /dev/md0 的分区布局如下:
$ sudo fdisk -l /dev/md0
Disk /dev/md0: 128.1 GiB, 137544859648 bytes, 268642304 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: gpt
Disk identifier: 126C8DF4-4BE7-4DC3-80C3-B47DAE679207
Device Start End Sectors Size Type
/dev/md0p1 2048 204799 202752 99M EFI System
/dev/md0p2 204800 268640255 268435456 128G Microsoft basic data
写入EFI分区
推荐使用virt-manager进行接下来的操作,virt-manager使用的具体操作过程不进行详细描述
在virt-manager中配置一个Win10 VM,配置要点如下:
- 芯片组Q35,固件UEFI
- 使用Windows ISO作为第一启动项
- 使用 /dev/md0 作为VM硬盘,类型设定为 SATA
配置完成后启动VM,进入ISO的系统安装流程,一直点击下一步,直到最后确认安装方式时选择“自定义”,随后进入分区界面。通过快捷键Shift+F10调出CMD,输入如下指令:
diskpart DISKPART> list disk DISKPART> select disk 0 # 选择/dev/md0在VM中对应的硬盘 DISKPART> list volume # 在分区列表中记下EFI分区序号 DISKPART> select volume 2 # 选择EFI分区 DISKPART> assign letter=B # 为EFI分区分配驱动器号(B:) DISKPART> exit
最后将驱动器 C: 中的系统启动信息写入到驱动器B: EFI分区 :
bcdboot C:\Windows /s B: /f ALL
注意:这里的驱动器驱动器C:指代线性阵列中Windows安装的分区 不清楚是否可能会被分配为其他驱动器号。使用命令时建议核实好分区和驱动器号的对应关系 正常情况下该命令总是能执行成功,执行失败则说明创建线性阵列/dev/md0时分区操作出现问题 通常是第二个分区(Win10物理分区)的结束扇区参数不匹配所致,请核对1.3节操作以纠正问题
EFI分区启动信息写入成功后关闭VM,将第一启动项改为 /dev/md0对应的硬盘 ,即可启动物理分区的Win10系统
SMB文件共享
现在已经成功启动了物理分区的Win10系统,还需要解决Host和VM交换文件数据的问题
因为使用的是物理分区作为VM的硬盘,其文件系统是Windows原生支持的NTFS。而为保持最大兼容性,将使用 SMB 把某个路径共享给Host,而不通过Host挂载NTFS分区再利用VioFS映射到VM的形式进行共享
关于SMB不过多赘述,直接参考 https://phoenixnap.com/kb/linux-mount-cifs 即可
值得一提的是,若想以非root用户身份挂载SMB路径,则需在/etc/fstab中写入对应的条目,如:
# win10 smb vmshare //192.168.141.77/D /mnt/win10-extorage cifs credentials=/etc/smb-credentials/win10-vmshare,rw,suid,dev,exec,noauto,user,async 0 0
其中:
- user参数 表示任意用户均可挂载
- noauto参数 表示系统启动时不进行自动挂载
配置完成后,用以下命令进行挂载(无需使用sudo):
mount /mnt/win10-extorage
VM性能调优
使用Virtio-SCSI驱动硬盘
此前我们使用SATA驱动硬盘启动,为提升硬盘性能,建议将其切换为Virtio-SCSI
首先需要在VM的xml文件中 添加 一个 virtio-scsi controller 并 删除 其余 scsi controller :
<controller type="scsi" model="virtio-scsi"/>
然后启动VM(此时硬盘还是SATA驱动),以管理员身份运行powershell,执行以下命令:
bcdedit /set "{current}" safeboot minimal
之后为VM安装 virtio-win 驱动,并关闭VM。再次启动VM将会进入安全模式,该模式下将自动装载所有驱动,包括virtio。后续正常启动将会自动装载并使用virtio驱动,安全模式下使用powershell关闭安全启动即可:
bcdedit /deletevalue "{current}" safeboot
关闭VM,修改xml配置,将硬盘改为Virtio-SCSI驱动:
<disk> ... <target bus="scsi"/> ... </disk>
再次启动VM即可。注意启动后应将Windows的 磁盘碎片整理服务 关闭
Virtio-SCSI似乎会使这个服务一直启动,导致极高的内存和CPU占用 实际上在固态硬盘上进行碎片整理没有必要,会极大地影响使用寿命 而如果是机械硬盘,则根本不需要Virtio-SCSI调优...
CPU Pin
CPU pin目的是将 QEMU/KVM相关进程 绑定 到 某些特定的核心 运行,减少其在不同CPU核心上的切换开销,提升VM性能。在进行CPU pin之前,先使用 lstopo 命令查看CPU拓扑:
sudo apt install hwloc # 安装相应软件包 lstopo --no-io
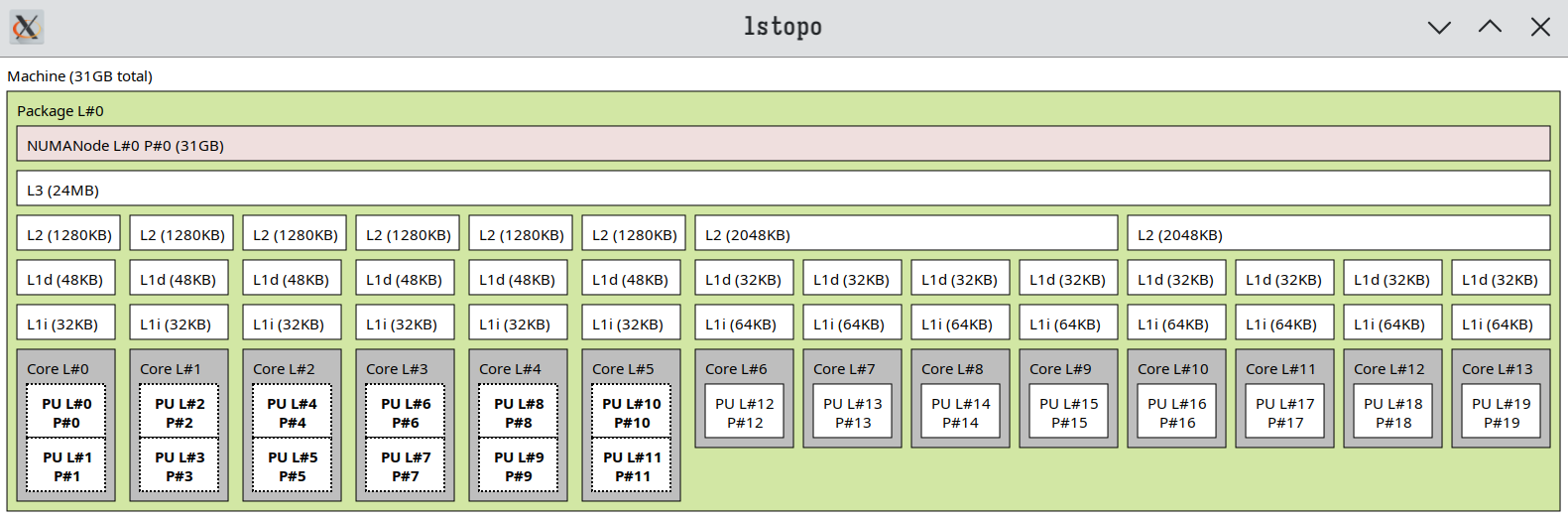
CPU pin的原则是 保持VM和Host拥有相同的CPU配置
若VM配置为支持超线程特性,则从第0个vCPU开始,每两个vCPU视作为一个core,如:(0, 1)、(2, 3) 超线程的VM CPU配置也应和Host一样,也就是将Host CPU中同属一个core的threads分配给VM CPU的同一个core
注意:不要把所有的threads都分配给VM,以免造成Host卡顿从而达到相反的效果。这里Host CPU是大小核架构,按照个人需求,将所有的小核(E-core)和一颗大核(P-core)分配给VM:
<vcpu placement="static">8</vcpu> <iothreads>1</iothreads> <cputune> <vcpupin vcpu='0' cpuset='12'/> <vcpupin vcpu='1' cpuset='13'/> <vcpupin vcpu='2' cpuset='14'/> <vcpupin vcpu='3' cpuset='15'/> <vcpupin vcpu='4' cpuset='16'/> <vcpupin vcpu='5' cpuset='17'/> <vcpupin vcpu='6' cpuset='18'/> <vcpupin vcpu='7' cpuset='19'/> <emulatorpin cpuset='10-11'/> <iothreadpin iothread='1' cpuset='10-11'/> </cputune> ... <cpu mode="host-passthrough" check="none" migratable="on"> <topology sockets="1" dies="1" cores="8" threads="1"/> <cache mode="passthrough"/> <maxphysaddr mode="passthrough" limit="40"/> </cpu>
配置中的cpuset对应逻辑CPU( 用小写的cpu表示逻辑CPU ),对应 lstopo 命令中 PU P# 的概念,即 Processing Unit Processor ,是CPU每个core中的处理单元,也就是超线程技术中的 thread 。在大小核架构下,一个大核拥有两个处理单元,一个小核只有一个。VM配置中 emulatorpin 和 iothreadpin 是I/O相关线程,在存在大量I/O请求的场景下应该pin不同的cpu
对于普通的Win10 VM,I/O并不密集,因此pin相同的cpu以节省资源 但要注意这两者不要和vcpupin的cpu有重叠,否则会降低VM运行性能
CPU pin只是第一步,后续要确保Host不在这些pin过的cpu上分配任务,从而不跟VM抢占资源,需要进行 cpu隔离
可以用Libvirt hook来实现,详见3.1 Cpu隔离Hook
内存调优
QEMU/KVM默认使用 2MB 的透明大页内存,在VM启动时将根据配置的VM内存大小,自动锁定相应数量的内存大页,让VM独占以提升性能
本人使用的Ubuntu 23.10内核已将大页设置为madvise模式,即系统默认启用透明大页,无需对大页配置进行更改
需确保在VM启动时有足够多的连续2MB内存,可供QEMU/KVM申请足够数量的内存大页即可
该需求可以通过3.2 内存优化Hook实现,该hook用来对Host内存进行回收、压缩以释放足够内存空间 查看此 https://wiki.archlinux.org/title/PCI_passthrough_via_OVMF#Transparent_huge_pages 以了解更多大页相关配置
Libvirt Hooks
Libvirt hook提供一种在 libvirt服务 某个 生命周期 执行 特定脚本 的能力,hook脚本放置在 /etc/libvirt/hooks 目录,关于VM管理的脚本入口文件是 /etc/libvirt/hooks/qemu ,其默认用法如下:
/etc/libvirt/hooks/qemu $vm_name $hook_name $sub_name $extra
更多信息请查阅:https://www.libvirt.org/hooks.html 要使用这个hook,需要判断VM实例名称、hook名称、子动作名称等参数,颇为不便
在这里使用 VFIO-Tools Hook Helper 对hook使用流程进行简化。Libvirt hook helper实际上是一个脚本,内容如下:
#!/usr/bin/env bash # # Author: SharkWipf # # Copy this file to /etc/libvirt/hooks, make sure it's called "qemu". # After this file is installed, restart libvirt. # From now on, you can easily add per-guest qemu hooks. # Add your hooks in /etc/libvirt/hooks/qemu.d/vm_name/hook_name/state_name. # For a list of available hooks, please refer to https://www.libvirt.org/hooks.html # GUEST_NAME="$1" HOOK_NAME="$2" STATE_NAME="$3" MISC="${@:4}" BASEDIR="$(dirname $0)" HOOKPATH="$BASEDIR/qemu.d/$GUEST_NAME/$HOOK_NAME/$STATE_NAME" set -e # If a script exits with an error, we should as well. # check if it's a non-empty executable file if [ -f "$HOOKPATH" ] && [ -s "$HOOKPATH" ] && [ -x "$HOOKPATH" ]; then eval \"$HOOKPATH\" "$@" elif [ -d "$HOOKPATH" ]; then while read file; do # check for null string if [ ! -z "$file" ]; then eval \"$file\" "$@" fi done <<< "$(find -L "$HOOKPATH" -maxdepth 1 -type f -executable -print;)" fi
简单来说就是优化了hook脚本的管理方式
安装完hook helper后重启libvirtd服务,即可通过如下结构管理VM hook:
/etc/libvirt/hooks/qemu.d/$vm_name/$hook_name/$sub_name/*
例如名称为win10的VM,其prepare hook、begin子动作要执行的脚本是setup.sh,则将脚本放在如下位置:
/etc/libvirt/hooks/qemu.d/win10/prepare/begin/setup.sh
Hook数量不限,类型不限定是shell脚本,指定任何解释器均可。较为重要的几个hook类型如下:
# Before a VM is started, before resources are allocated: /etc/libvirt/hooks/qemu.d/$vm_name/prepare/begin/* # Before a VM is started, after resources are allocated: /etc/libvirt/hooks/qemu.d/$vm_name/start/begin/* # After a VM has started up: /etc/libvirt/hooks/qemu.d/$vm_name/started/begin/* # After a VM has shut down, before releasing its resources: /etc/libvirt/hooks/qemu.d/$vm_name/stopped/end/* # After a VM has shut down, after resources are released: /etc/libvirt/hooks/qemu.d/$vm_name/release/end/*
接下来以上述Win10 VM为例,创建若干启动和停止hook,分别用来实现cpu隔离、大页分配和cpu释放等操作自动化
Cpu隔离Hook
创建脚本 /etc/libvirt/hooks/qemu.d/win10/isolate-cpus.sh ,用于实现cpu隔离和恢复(只需隔离vcpupin配置的cpu):
#!/usr/bin/env bash # # Original author: Rokas Kupstys <rokups@zoho.com> # Heavily modified by: Danny Lin <danny@kdrag0n.dev> # And by ME: https://github.com/yjzzjy4 # # Use systemd to isolate pinned cpus. # # Target file locations: # - $SYSCONFDIR/hooks/qemu.d/$vm_name/prepare/begin/isolate-cpus.sh # - $SYSCONFDIR/hooks/qemu.d/$vm_name/release/end/isolate-cpus.sh # $SYSCONFDIR usually is /etc/libvirt. # ALL_CPUS='0-19' HOST_CPUS='0-11' # Cpus reserved for host VIRT_CPUS='12-19' # Cpus reserved for virtual machine(s) VM_NAME="$1" VM_ACTION="$2/$3" function isolate_cpus() { systemctl set-property --runtime -- user.slice AllowedCPUs=$HOST_CPUS systemctl set-property --runtime -- system.slice AllowedCPUs=$HOST_CPUS systemctl set-property --runtime -- init.scope AllowedCPUs=$HOST_CPUS } function unisolate_cpus() { systemctl set-property --runtime -- user.slice AllowedCPUs=$ALL_CPUS systemctl set-property --runtime -- system.slice AllowedCPUs=$ALL_CPUS systemctl set-property --runtime -- init.scope AllowedCPUs=$ALL_CPUS } # For convenient manual invocation if [[ "$VM_NAME" == "shield" ]]; then isolate_cpus exit 0 elif [[ "$VM_NAME" == "unshield" ]]; then unisolate_cpus exit 0 fi if [[ "$VM_ACTION" == "prepare/begin" ]]; then echo "libvirt-qemu systemd: Reserving CPUs $VIRT_CPUS for VM $VM_NAME" > /dev/kmsg 2>&1 isolate_cpus > /dev/kmsg 2>&1 echo "libvirt-qemu systemd: Successfully reserved CPUs $VIRT_CPUS" > /dev/kmsg 2>&1 elif [[ "$VM_ACTION" == "release/end" ]]; then echo "libvirt-qemu systemd: Releasing CPUs $VIRT_CPUS from VM $VM_NAME" > /dev/kmsg 2>&1 unisolate_cpus > /dev/kmsg 2>&1 echo "libvirt-qemu systemd: Successfully released CPUs $VIRT_CPUS" > /dev/kmsg 2>&1 fi
内存优化Hook
创建脚本 /etc/libvirt/hooks/qemu.d/win10/better-hugepages.sh ,用于回收并压缩内存,使VM启动时有足够的连续内存作为透明大页使用:
#!/usr/bin/env bash # # Author: SharkWipf (https://github.com/SharkWipf) # # This file depends on the PassthroughPOST hook helper script found here: # https://github.com/PassthroughPOST/VFIO-Tools/tree/master/libvirt_hooks # This hook only needs to run on `prepare/begin`, not on stop. # Place this script in this directory: # $SYSCONFDIR/libvirt/hooks/qemu.d/your_vm/prepare/begin/ # $SYSCONFDIR usually is /etc/libvirt. # # This hook will help free and compact memory to ease THP allocation. # QEMU VMs will use THP (Transparent HugePages) by default if enough # unfragmented memory can be found on startup. If your memory is very # fragmented, this may cause a slow VM startup (like a slowly responding # VM start button/command), and may cause QEMU to fall back to regular # memory pages, slowing down VM performance. # If you (suspect you) suffer from this, this hook will help ease THP # allocation so you don't need to resort to misexplained placebo scripts. # # Don't use the old hugepages.sh script in this repo. It's useless. # It's only kept in for archival reasons and offers no benefits. # # Finish writing any outstanding writes to disk. sync # Drop all filesystem caches to free up more memory. echo 3 > /proc/sys/vm/drop_caches # Do another run of writing any possible new outstanding writes. sync # Tell the kernel to "defragment" memory where possible. echo 1 > /proc/sys/vm/compact_memory
由于使用的是动态大页,VM关闭时Host系统会自动回收大页内存,因此better-hugepages.sh脚本仅需在VM启动时执行
上述两个脚本源自 https://github.com/PassthroughPOST/VFIO-Tools 第一个脚本修改为使用systemd隔离cpu,要使用cset,请参阅原地址
线性阵列启停Hook
根据此前的配置,Win10 VM的系统硬盘是一个线性软阵列 该阵列在Host重启后将不复存在,需要再次运行start-md0.sh脚本启动阵列
一个更好的做法是在VM启动时自动启动阵列,VM关闭后停止阵列,可以使用hook脚本实现该需求。将 start-md0.sh 和 stop-md0.sh 整合成一个hook脚本, /etc/libvirt/hooks/qemu.d/win10/manage-vdisk.sh :
#!/usr/bin/env bash # # Author: yjzzjy4 (https://github.com/yjzzjy4) # # This file creates and distroys /dev/md0 for booting physical Windows drive. # WIN_PART=/dev/nvme1n1p2 EFI_DIR=/etc/libvirt/hooks/qemu.d/win10/md0 VM_ACTION="$2/$3" if [[ "$VM_ACTION" == "prepare/begin" ]]; then if [[ -e /dev/md0 ]]; then echo "/dev/md0 already exists" > /dev/kmsg 2>&1 exit 1 fi if mountpoint -q -- "${WIN_PART}"; then echo "Unmounting ${WIN_PART}..." > /dev/kmsg 2>&1 umount ${WIN_PART} fi modprobe loop modprobe linear LOOP0=$(losetup -f "${EFI_DIR}/loop-efi0" --show) LOOP1=$(losetup -f "${EFI_DIR}/loop-efi1" --show) mdadm --build --verbose /dev/md0 --chunk=512 --level=linear --raid-devices=3 ${LOOP0} ${WIN_PART} ${LOOP1} chown $USER:disk /dev/md0 echo "$LOOP0 $LOOP1" > "${EFI_DIR}/.win10-loop-devices" elif [[ "$VM_ACTION" == "release/end" ]]; then mdadm --stop /dev/md0 xargs losetup -d < "${EFI_DIR}/.win10-loop-devices" fi
测试Hooks
将创建的所有hooks整理一下,利用软链接的形式存放到Win10 VM对应的生命周期目录中,最后得到如下结构:
$ tree -ah /etc/libvirt/hooks/qemu.d/win10 [4.0K] /etc/libvirt/hooks/qemu.d/win10 ├── [1.4K] better-hugepages.sh ├── [1.7K] isolate-cpus.sh ├── [ 950] manage-vdisk.sh ├── [4.0K] md0 │ ├── [100M] loop-efi0 │ ├── [1.0M] loop-efi1 │ └── [ 23] .win10-loop-devices ├── [4.0K] prepare │ └── [4.0K] begin │ ├── [ 21] 00-manage-vdisk.sh -> ../../manage-vdisk.sh │ ├── [ 25] 01-better-hugepages.sh -> ../../better-hugepages.sh │ └── [ 21] 02-isolate-cpus.sh -> ../../isolate-cpus.sh └── [4.0K] release └── [4.0K] end ├── [ 21] 00-isolate-cpus.sh -> ../../isolate-cpus.sh └── [ 21] 01-manage-vdisk.sh -> ../../manage-vdisk.sh 6 directories, 11 files
注意:这里没有写关于自动挂载SMB的hook,因为找不到一个合适的生命周期用于自动挂载。并且由于挂载操作是用户级的,且Host作为SMB的client。故建议需要使用的用户随用随挂载,只需运行一行命令(或者在文件管理器中点一下),操作简单
在VM关机之前先将SMB卸载即可,不卸载也没问题,反正也访问不了(报错:Host is down)
在启动Win10 VM之前,先记录一下系统状态,方便和启动后进行对比以验证hooks是否生效。首先是大页分配情况:
$ grep AnonHugePages /proc/meminfo AnonHugePages: 0 kB
可知系统此时没有使用任何大页内存。再查看dev/md0是否存在:
$ ls -al /dev | grep md0
未见任何输出,表示dev/md0不存在。最后查看CPU拓扑:
$ lstopo-no-graphics --no-bridges --no-io
Machine (31GB total) + Package L#0
NUMANode L#0 (P#0 31GB)
L3 L#0 (24MB)
L2 L#0 (1280KB) + L1d L#0 (48KB) + L1i L#0 (32KB) + Core L#0
PU L#0 (P#0)
PU L#1 (P#1)
L2 L#1 (1280KB) + L1d L#1 (48KB) + L1i L#1 (32KB) + Core L#1
PU L#2 (P#2)
PU L#3 (P#3)
L2 L#2 (1280KB) + L1d L#2 (48KB) + L1i L#2 (32KB) + Core L#2
PU L#4 (P#4)
PU L#5 (P#5)
L2 L#3 (1280KB) + L1d L#3 (48KB) + L1i L#3 (32KB) + Core L#3
PU L#6 (P#6)
PU L#7 (P#7)
L2 L#4 (1280KB) + L1d L#4 (48KB) + L1i L#4 (32KB) + Core L#4
PU L#8 (P#8)
PU L#9 (P#9)
L2 L#5 (1280KB) + L1d L#5 (48KB) + L1i L#5 (32KB) + Core L#5
PU L#10 (P#10)
PU L#11 (P#11)
L2 L#6 (2048KB)
L1d L#6 (32KB) + L1i L#6 (64KB) + Core L#6 + PU L#12 (P#12)
L1d L#7 (32KB) + L1i L#7 (64KB) + Core L#7 + PU L#13 (P#13)
L1d L#8 (32KB) + L1i L#8 (64KB) + Core L#8 + PU L#14 (P#14)
L1d L#9 (32KB) + L1i L#9 (64KB) + Core L#9 + PU L#15 (P#15)
L2 L#7 (2048KB)
L1d L#10 (32KB) + L1i L#10 (64KB) + Core L#10 + PU L#16 (P#16)
L1d L#11 (32KB) + L1i L#11 (64KB) + Core L#11 + PU L#17 (P#17)
L1d L#12 (32KB) + L1i L#12 (64KB) + Core L#12 + PU L#18 (P#18)
L1d L#13 (32KB) + L1i L#13 (64KB) + Core L#13 + PU L#19 (P#19)
Host系统可见所有的cpu,也可以使用所有的cpu。现在启动Win10 VM:
$ virsh start win10
Domain 'win10' started
再次检查大页分配情况:
$ grep AnonHugePages /proc/meminfo AnonHugePages: 8392704 kB
8392704KB=8196MB,Host系统为Win10 VM分配了8GB内存,即8192MB,说明QEMU/KVM在VM启动时已经锁定足额大页内存
然后查看dev/md0是否存在:
$ ls -al /dev | grep md0 brw-rw---- 1 root disk 9, 0 4月 25 23:16 md0 brw-rw---- 1 root disk 259, 7 4月 25 23:16 md0p1 brw-rw---- 1 root disk 259, 8 4月 25 23:16 md0p2
结果表明线性阵列dev/md0已存在,并被Win10 VM作为系统盘使用
最后查看CPU拓扑:
$ lstopo-no-graphics --no-bridges --no-io
Machine (31GB total) + Package L#0
NUMANode L#0 (P#0 31GB)
L3 L#0 (24MB)
L2 L#0 (1280KB) + L1d L#0 (48KB) + L1i L#0 (32KB) + Core L#0
PU L#0 (P#0)
PU L#1 (P#1)
L2 L#1 (1280KB) + L1d L#1 (48KB) + L1i L#1 (32KB) + Core L#1
PU L#2 (P#2)
PU L#3 (P#3)
L2 L#2 (1280KB) + L1d L#2 (48KB) + L1i L#2 (32KB) + Core L#2
PU L#4 (P#4)
PU L#5 (P#5)
L2 L#3 (1280KB) + L1d L#3 (48KB) + L1i L#3 (32KB) + Core L#3
PU L#6 (P#6)
PU L#7 (P#7)
L2 L#4 (1280KB) + L1d L#4 (48KB) + L1i L#4 (32KB) + Core L#4
PU L#8 (P#8)
PU L#9 (P#9)
L2 L#5 (1280KB) + L1d L#5 (48KB) + L1i L#5 (32KB) + Core L#5
PU L#10 (P#10)
PU L#11 (P#11)
此时Host的操作系统只能“看见”大核,所有小核正在被VM独占,因此在Host视角下,小核已经全部消失了
最后附上一张Host和VM的截图(两个系统分别在两个分辨率不同的显示器上,故截图有一部分是黑边):
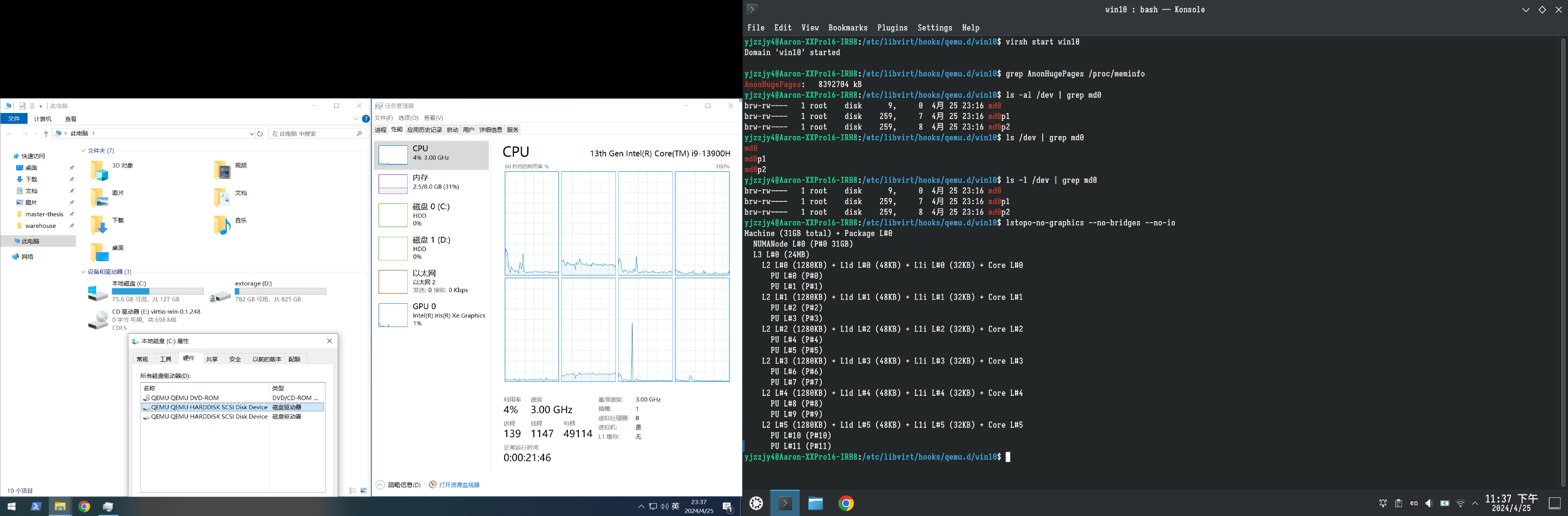
可以看到Win10 VM拥有8个核心、8个线程和8GB内存。CPU型号识别正常,且C:和D:驱动器均是QEMU的SCSI设备。关于SMB共享,也可以通过文件管理器正常挂载,如图:
VM关闭后,上述配置将被逆转,即在Host操作系统上恢复原样。至此所有hooks均生效,VM配置和性能调优均已完成